Bit-Shrinking: Limiting Instantaneous Sharpness for Improving Post-Training Quantization
{kind=link}
Abstract
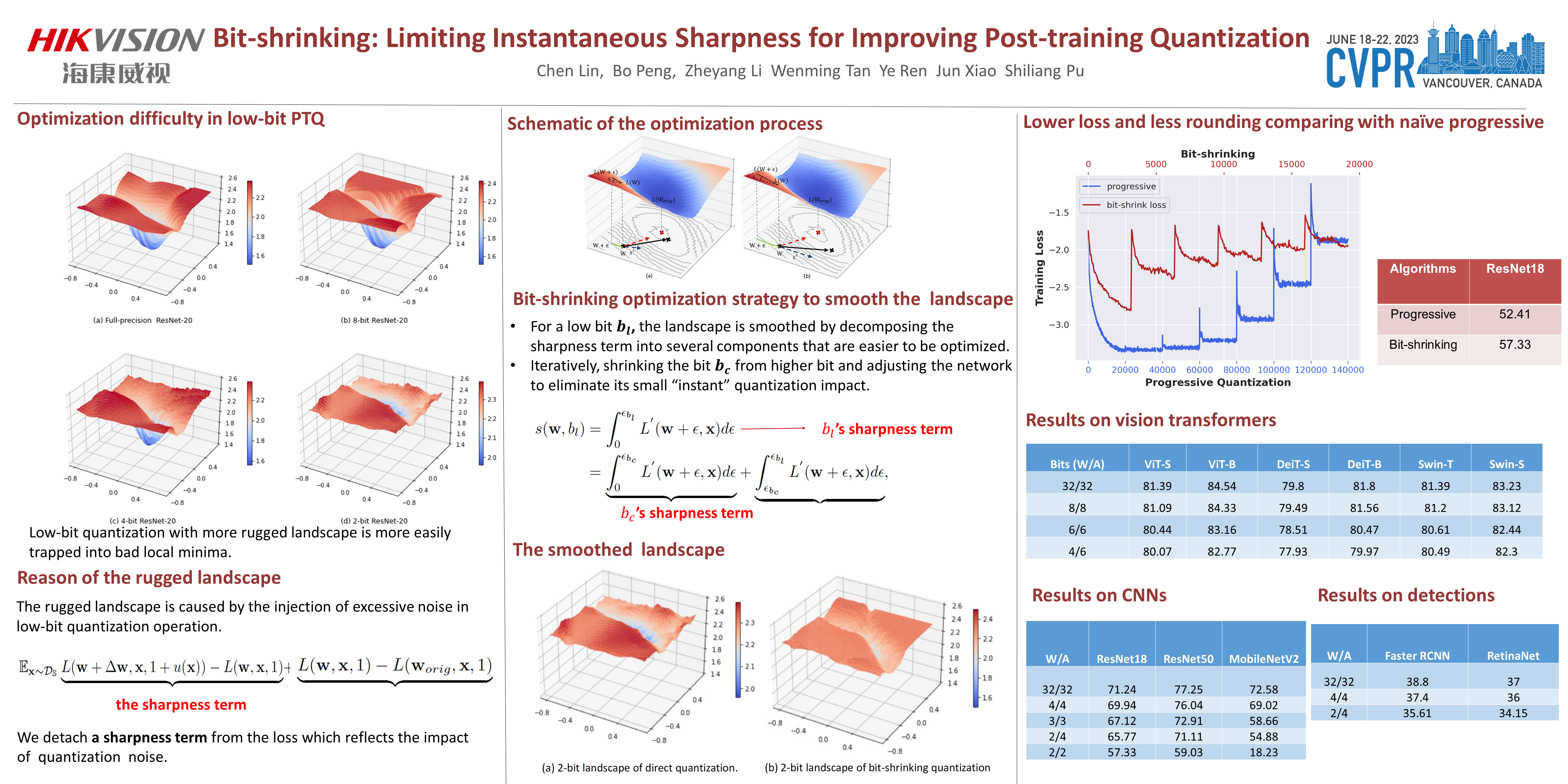
Post-training quantization (PTQ) is an effective compression method to reduce the model size and computational cost. However, quantizing a model into a low-bit one, e.g., lower than 4, is difficult and often results in nonnegligible performance degradation. To address this, we investigate the loss landscapes of quantized networks with various bit-widths. We show that the network with more ragged loss surface, is more easily trapped into bad local minima, which mostly appears in low-bit quantization. A deeper analysis indicates, the ragged surface is caused by the injection of excessive quantization noise. To this end, we detach a sharpness term from the loss which reflects the impact of quantization noise. To smooth the rugged loss surface, we propose to limit the sharpness term small and stable during optimization. Instead of directly optimizing the target bit network, the bit-width of quantized network has a self-adapted shrinking scheduler in continuous domain from high bit-width to the target by limiting the increasing sharpness term within a proper range. It can be viewed as iteratively adding small “instant” quantization noise and adjusting the network to eliminate its impact. Widely experiments including classification and detection tasks demonstrate the effectiveness of the Bit-shrinking strategy in PTQ. On the Vision Transformer models, our INT8 and INT6 models drop within 0.5% and 1.5% Top-1 accuracy, respectively. On the traditional CNN networks, our INT4 quantized models drop within 1.3% and 3.5% Top-1 accuracy on ResNet18 and MobileNetV2 without fine-tuning, which achieves the state-of-the-art performance.