A Practical Upper Bound for the Worst-Case Attribution Deviations
{kind=link}
Abstract
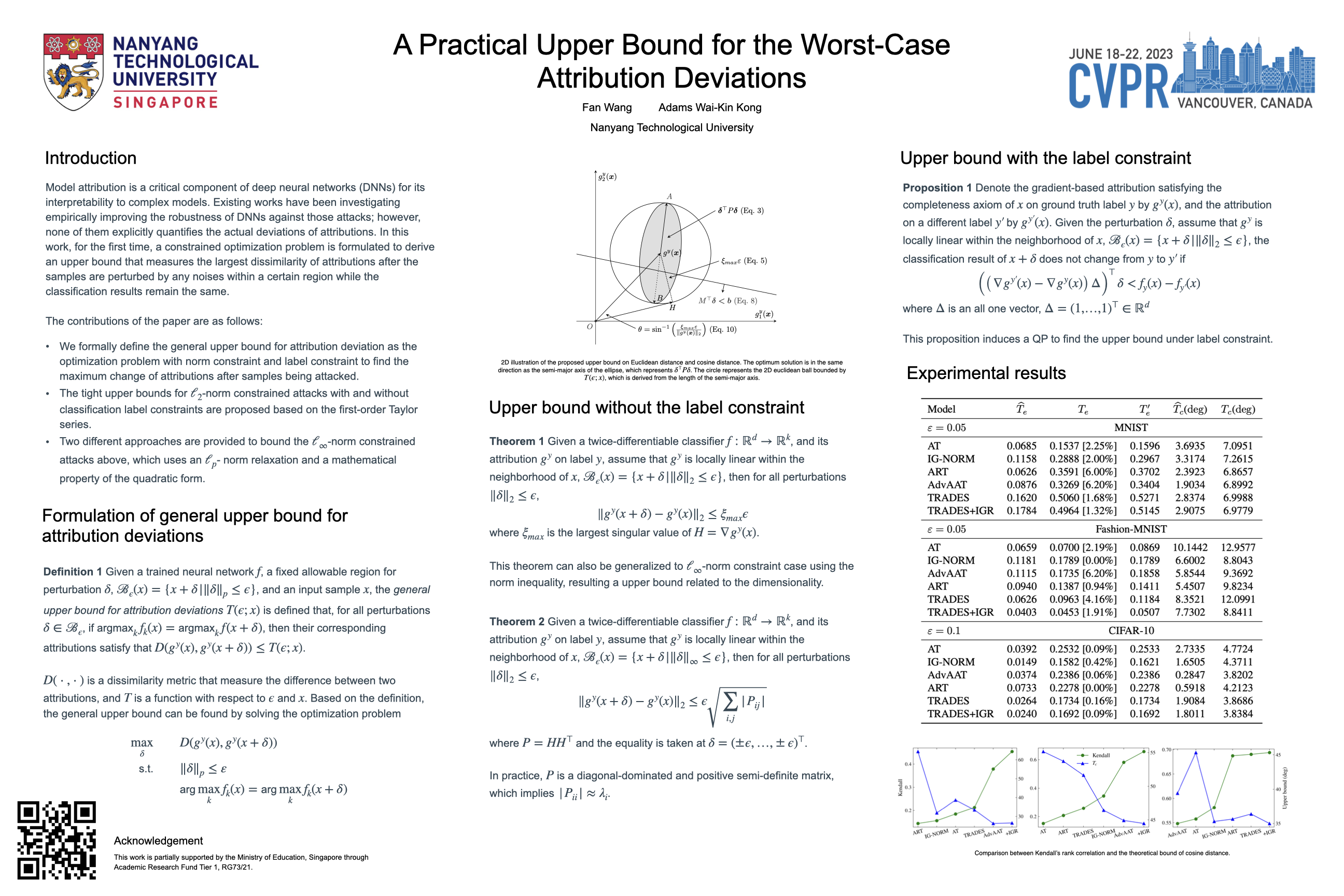
Model attribution is a critical component of deep neural networks (DNNs) for its interpretability to complex models. Recent studies bring up attention to the security of attribution methods as they are vulnerable to attribution attacks that generate similar images with dramatically different attributions. Existing works have been investigating empirically improving the robustness of DNNs against those attacks; however, none of them explicitly quantifies the actual deviations of attributions. In this work, for the first time, a constrained optimization problem is formulated to derive an upper bound that measures the largest dissimilarity of attributions after the samples are perturbed by any noises within a certain region while the classification results remain the same. Based on the formulation, different practical approaches are introduced to bound the attributions above using Euclidean distance and cosine similarity under both L2 and Linf-norm perturbations constraints. The bounds developed by our theoretical study are validated on various datasets and two different types of attacks (PGD attack and IFIA attribution attack). Over 10 million attacks in the experiments indicate that the proposed upper bounds effectively quantify the robustness of models based on the worst-case attribution dissimilarities.