A Data-Based Perspective on Transfer Learning
Saachi Jain ⋅ Hadi Salman ⋅ Alaa Khaddaj ⋅ Eric Wong ⋅ Sung Min Park ⋅ Aleksander Mądry
2023 Poster
{kind=link}
Abstract
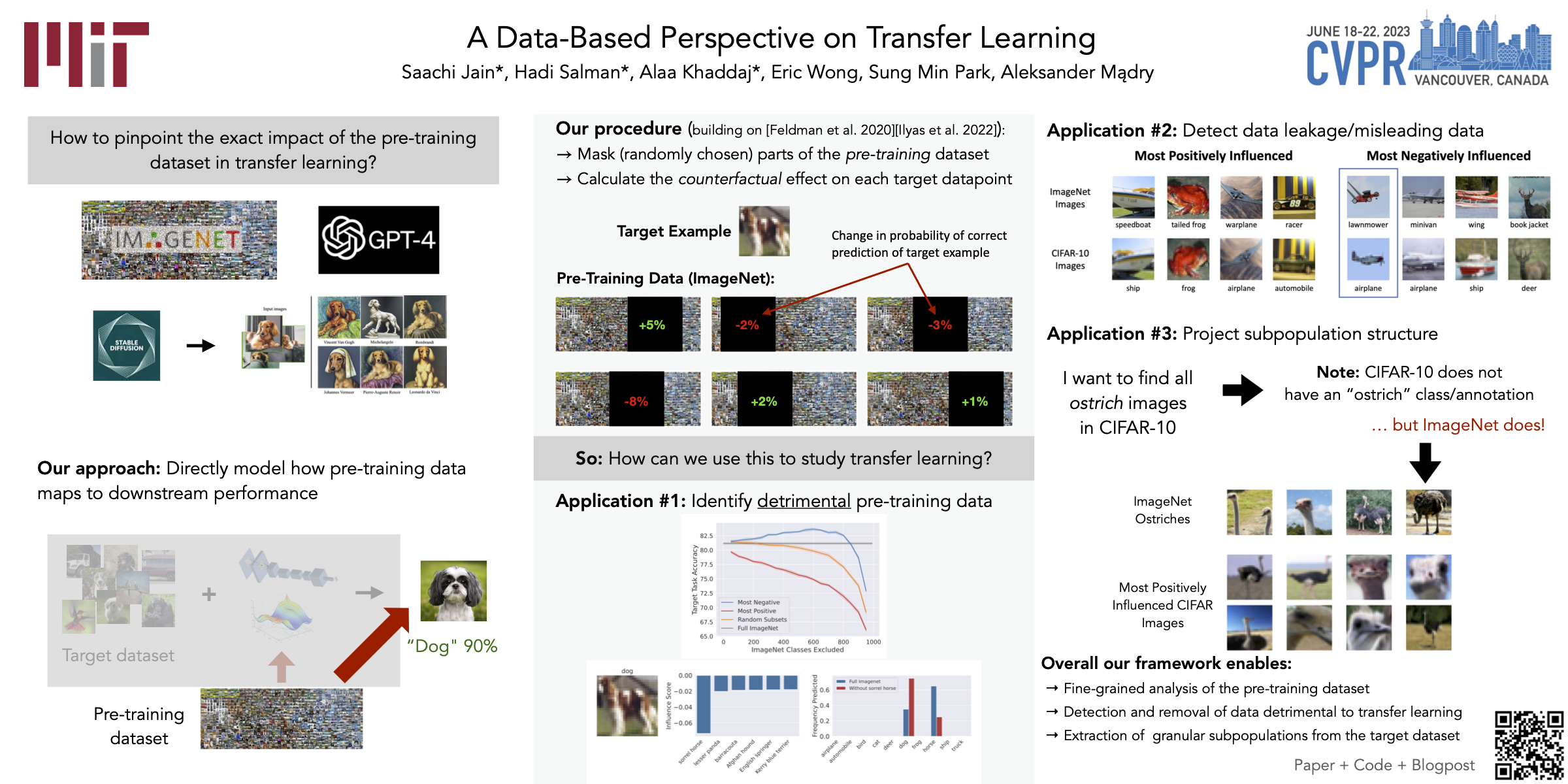
It is commonly believed that more pre-training data leads to better transfer learning performance. However, recent evidence suggests that removing data from the source dataset can actually help too. In this work, we present a framework for probing the impact of the source dataset’s composition on transfer learning performance. Our framework facilitates new capabilities such as identifying transfer learning brittleness and detecting pathologies such as data-leakage and the presence of misleading examples in the source dataset. In particular, we demonstrate that removing detrimental datapoints identified by our framework improves transfer performance from ImageNet on a variety of transfer tasks.
Chat is not available.
Successful Page Load