Clothed Human Performance Capture With a Double-Layer Neural Radiance Fields
{kind=link}
Abstract
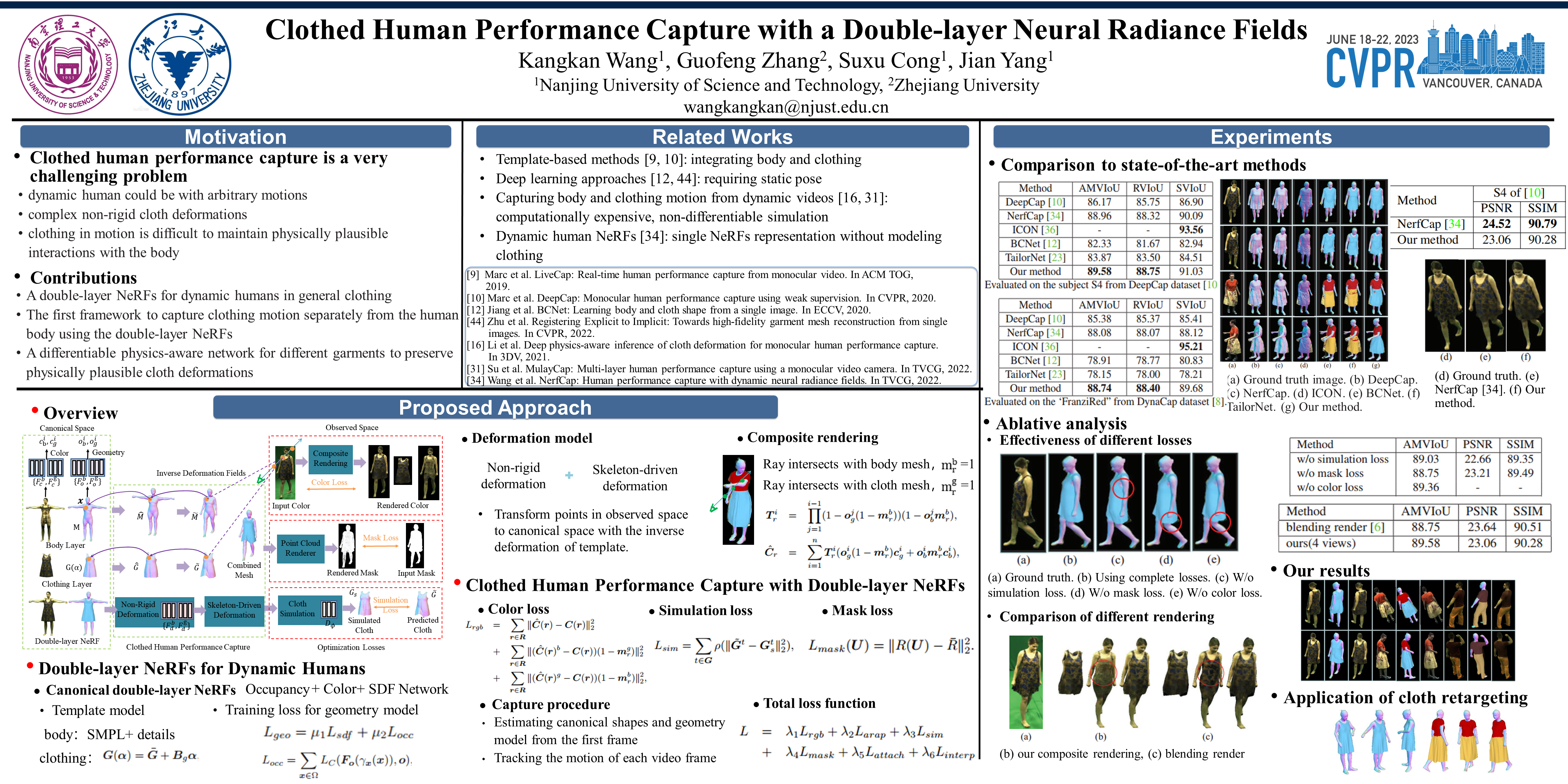
This paper addresses the challenge of capturing performance for the clothed humans from sparse-view or monocular videos. Previous methods capture the performance of full humans with a personalized template or recover the garments from a single frame with static human poses. However, it is inconvenient to extract cloth semantics and capture clothing motion with one-piece template, while single frame-based methods may suffer from instable tracking across videos. To address these problems, we propose a novel method for human performance capture by tracking clothing and human body motion separately with a double-layer neural radiance fields (NeRFs). Specifically, we propose a double-layer NeRFs for the body and garments, and track the densely deforming template of the clothing and body by jointly optimizing the deformation fields and the canonical double-layer NeRFs. In the optimization, we introduce a physics-aware cloth simulation network which can help generate physically plausible cloth dynamics and body-cloth interactions. Compared with existing methods, our method is fully differentiable and can capture both the body and clothing motion robustly from dynamic videos. Also, our method represents the clothing with an independent NeRFs, allowing us to model implicit fields of general clothes feasibly. The experimental evaluations validate its effectiveness on real multi-view or monocular videos.