Knowledge Distillation for 6D Pose Estimation by Aligning Distributions of Local Predictions
{kind=link}
Abstract
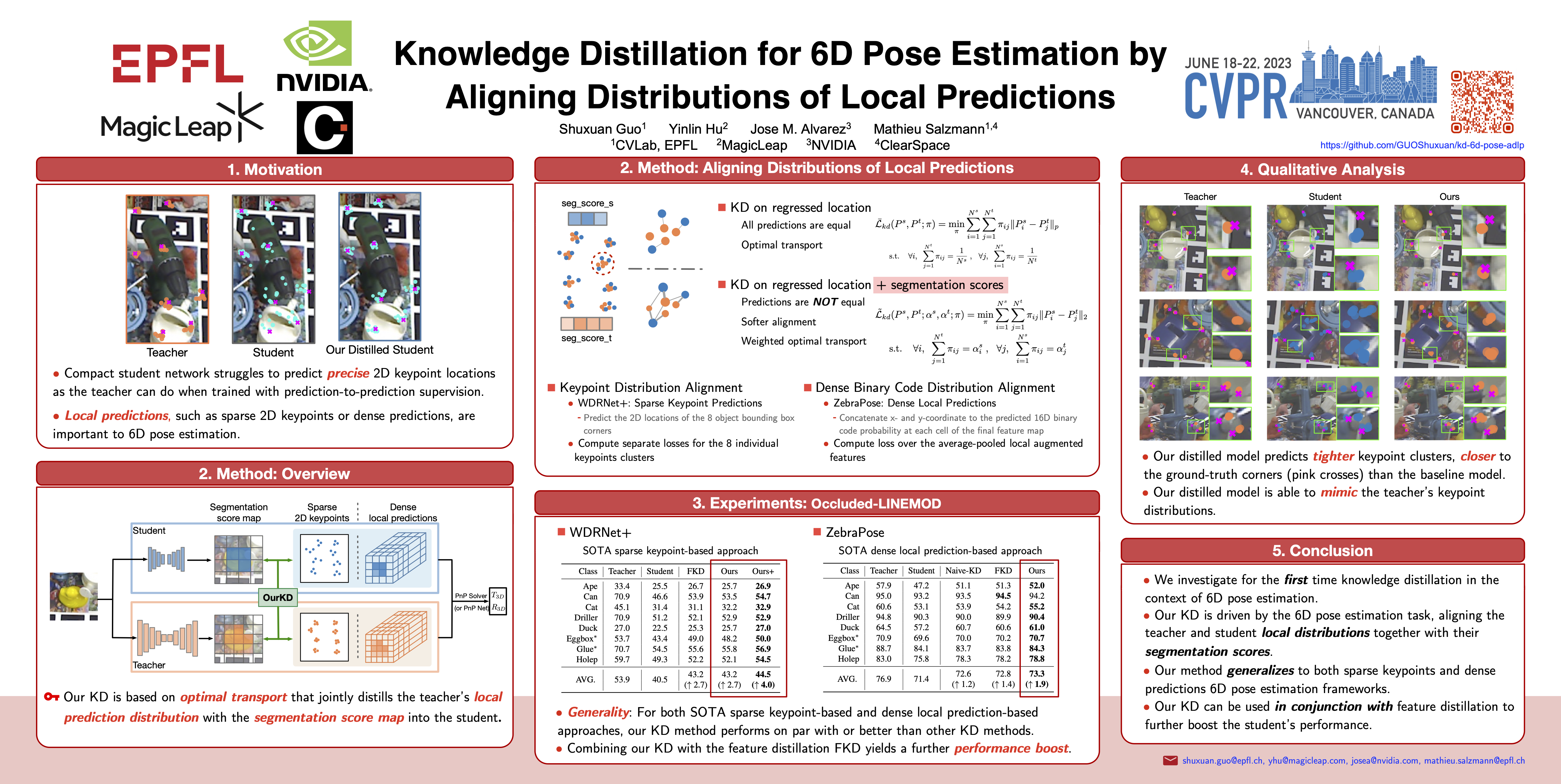
Knowledge distillation facilitates the training of a compact student network by using a deep teacher one. While this has achieved great success in many tasks, it remains completely unstudied for image-based 6D object pose estimation. In this work, we introduce the first knowledge distillation method driven by the 6D pose estimation task. To this end, we observe that most modern 6D pose estimation frameworks output local predictions, such as sparse 2D keypoints or dense representations, and that the compact student network typically struggles to predict such local quantities precisely. Therefore, instead of imposing prediction-to-prediction supervision from the teacher to the student, we propose to distill the teacher’s distribution of local predictions into the student network, facilitating its training. Our experiments on several benchmarks show that our distillation method yields state-of-the-art results with different compact student models and for both keypoint-based and dense prediction-based architectures.