FeatureBooster: Boosting Feature Descriptors With a Lightweight Neural Network
{kind=link}
Abstract
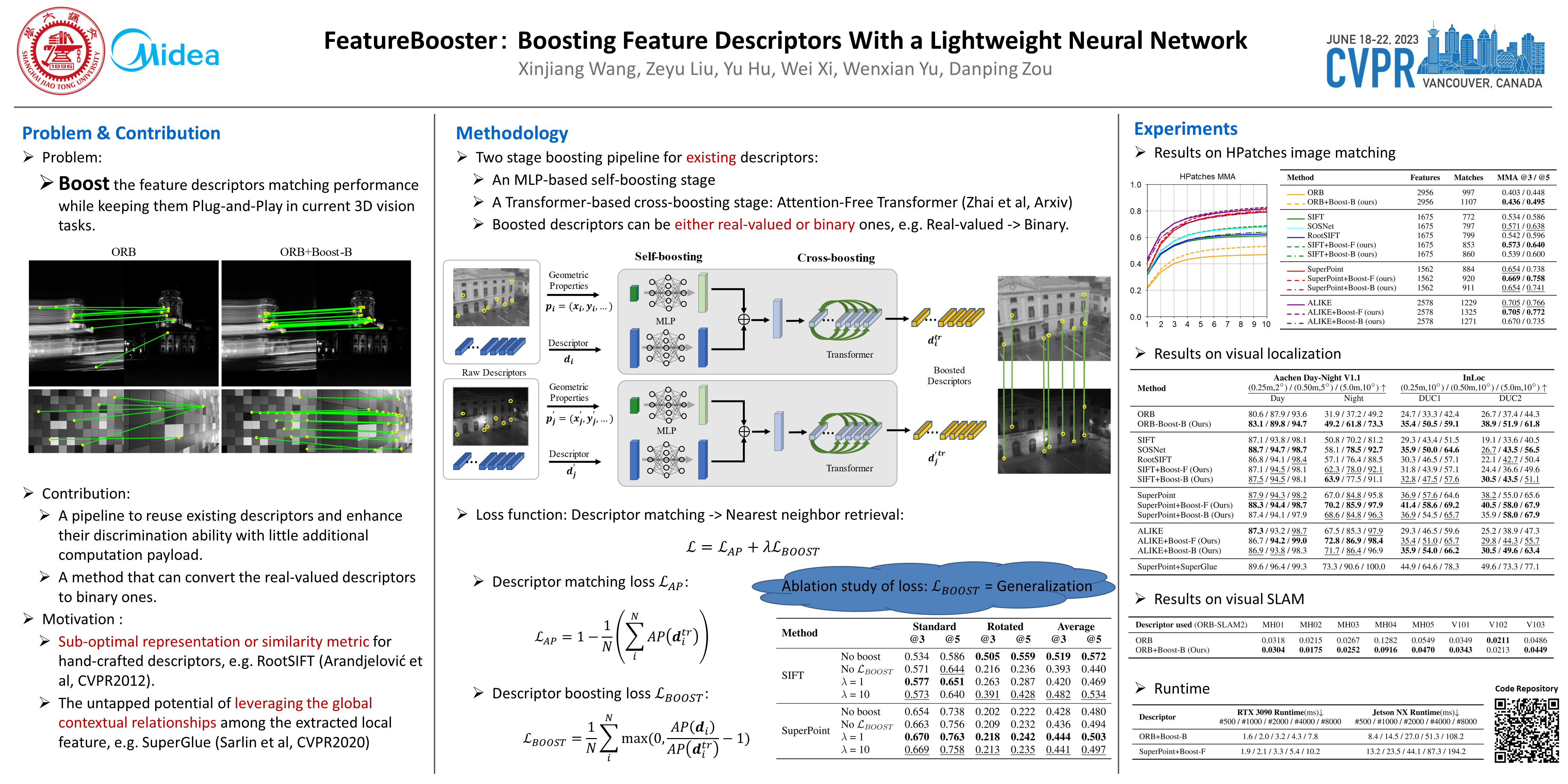
We introduce a lightweight network to improve descriptors of keypoints within the same image. The network takes the original descriptors and the geometric properties of keypoints as the input, and uses an MLP-based self-boosting stage and a Transformer-based cross-boosting stage to enhance the descriptors. The boosted descriptors can be either real-valued or binary ones. We use the proposed network to boost both hand-crafted (ORB, SIFT) and the state-of-the-art learning-based descriptors (SuperPoint, ALIKE) and evaluate them on image matching, visual localization, and structure-from-motion tasks. The results show that our method significantly improves the performance of each task, particularly in challenging cases such as large illumination changes or repetitive patterns. Our method requires only 3.2ms on desktop GPU and 27ms on embedded GPU to process 2000 features, which is fast enough to be applied to a practical system. The code and trained weights are publicly available at github.com/SJTU-ViSYS/FeatureBooster.