Probabilistic Debiasing of Scene Graphs
{kind=link}
Abstract
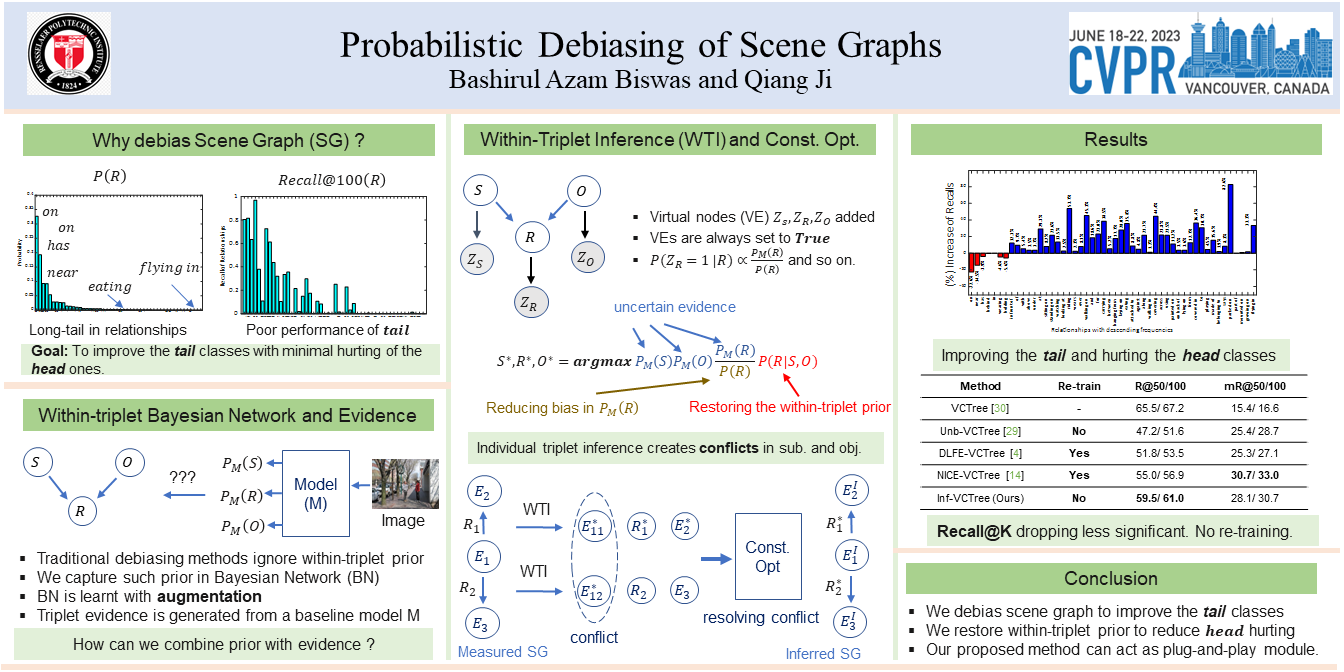
The quality of scene graphs generated by the state-of-the-art (SOTA) models is compromised due to the long-tail nature of the relationships and their parent object pairs. Training of the scene graphs is dominated by the majority relationships of the majority pairs and, therefore, the object-conditional distributions of relationship in the minority pairs are not preserved after the training is converged. Consequently, the biased model performs well on more frequent relationships in the marginal distribution of relationships such as ‘on’ and ‘wearing’, and performs poorly on the less frequent relationships such as ‘eating’ or ‘hanging from’. In this work, we propose virtual evidence incorporated within-triplet Bayesian Network (BN) to preserve the object-conditional distribution of the relationship label and to eradicate the bias created by the marginal probability of the relationships. The insufficient number of relationships in the minority classes poses a significant problem in learning the within-triplet Bayesian network. We address this insufficiency by embedding-based augmentation of triplets where we borrow samples of the minority triplet classes from its neighboring triplets in the semantic space. We perform experiments on two different datasets and achieve a significant improvement in the mean recall of the relationships. We also achieve a better balance between recall and mean recall performance compared to the SOTA de-biasing techniques of scene graph models.