TempSAL – Uncovering Temporal Information for Deep Saliency Prediction
{kind=link}
Abstract
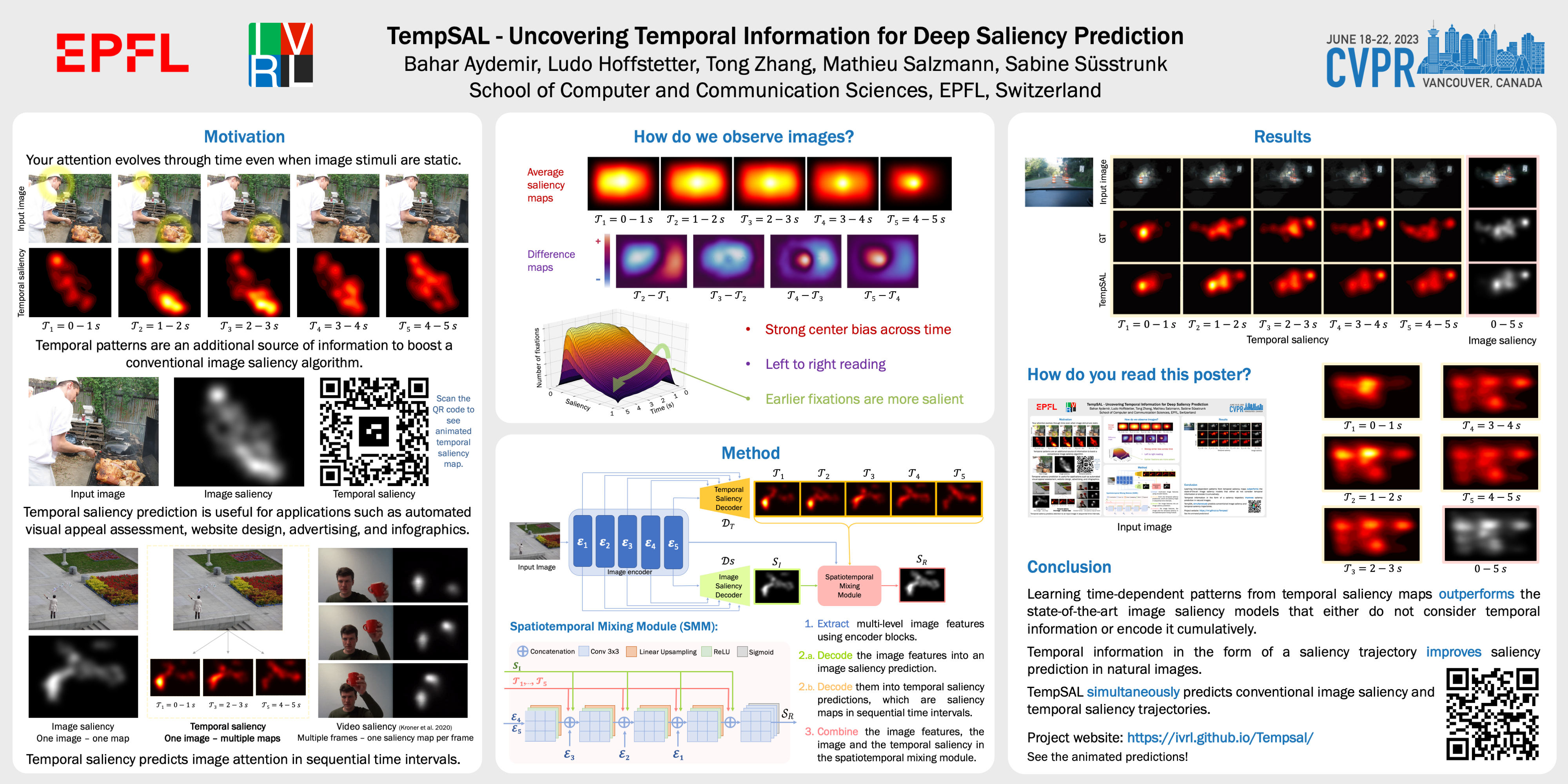
Deep saliency prediction algorithms complement the object recognition features, they typically rely on additional information such as scene context, semantic relationships, gaze direction, and object dissimilarity. However, none of these models consider the temporal nature of gaze shifts during image observation. We introduce a novel saliency prediction model that learns to output saliency maps in sequential time intervals by exploiting human temporal attention patterns. Our approach locally modulates the saliency predictions by combining the learned temporal maps. Our experiments show that our method outperforms the state-of-the-art models, including a multi-duration saliency model, on the SALICON benchmark and CodeCharts1k dataset. Our code is publicly available on GitHub.