SCOTCH and SODA: A Transformer Video Shadow Detection Framework
{kind=link}
Abstract
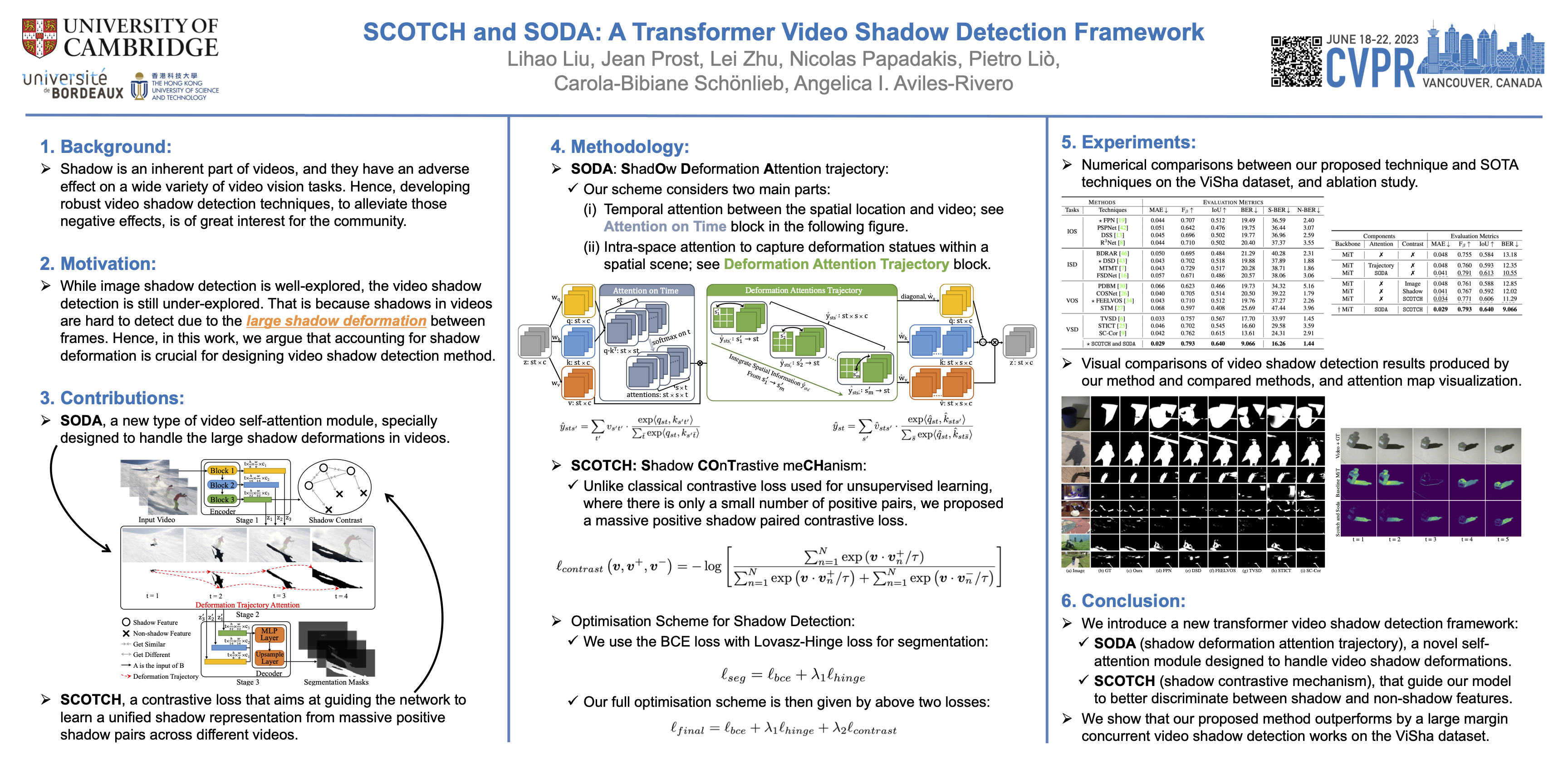
Shadows in videos are difficult to detect because of the large shadow deformation between frames. In this work, we argue that accounting for shadow deformation is essential when designing a video shadow detection method. To this end, we introduce the shadow deformation attention trajectory (SODA), a new type of video self-attention module, specially designed to handle the large shadow deformations in videos. Moreover, we present a new shadow contrastive learning mechanism (SCOTCH) which aims at guiding the network to learn a unified shadow representation from massive positive shadow pairs across different videos. We demonstrate empirically the effectiveness of our two contributions in an ablation study. Furthermore, we show that SCOTCH and SODA significantly outperforms existing techniques for video shadow detection. Code is available at the project page: https://lihaoliu-cambridge.github.io/scotchandsoda/