SelfME: Self-Supervised Motion Learning for Micro-Expression Recognition
{kind=link}
Abstract
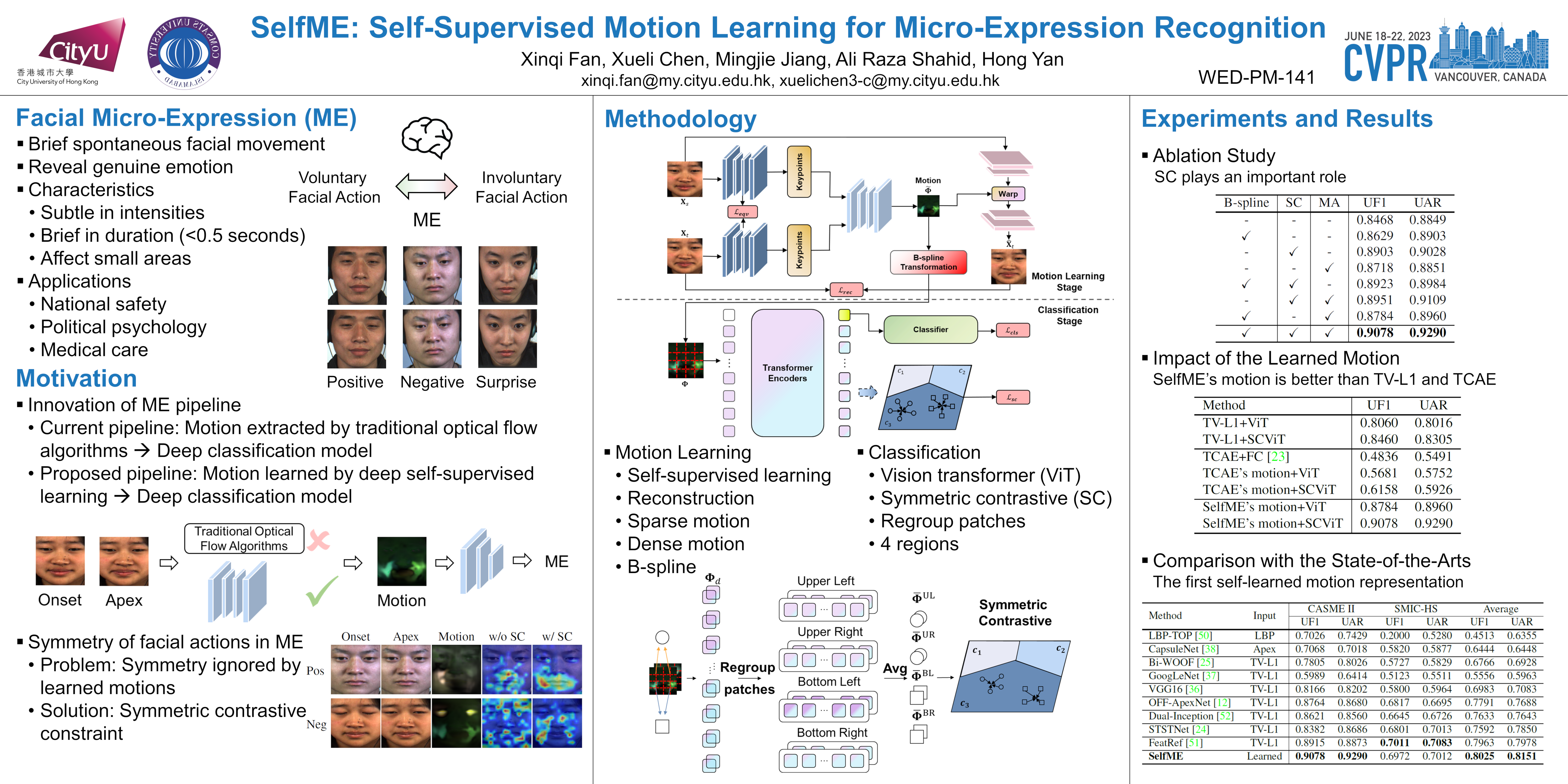
Facial micro-expressions (MEs) refer to brief spontaneous facial movements that can reveal a person’s genuine emotion. They are valuable in lie detection, criminal analysis, and other areas. While deep learning-based ME recognition (MER) methods achieved impressive success, these methods typically require pre-processing using conventional optical flow-based methods to extract facial motions as inputs. To overcome this limitation, we proposed a novel MER framework using self-supervised learning to extract facial motion for ME (SelfME). To the best of our knowledge, this is the first work using an automatically self-learned motion technique for MER. However, the self-supervised motion learning method might suffer from ignoring symmetrical facial actions on the left and right sides of faces when extracting fine features. To address this issue, we developed a symmetric contrastive vision transformer (SCViT) to constrain the learning of similar facial action features for the left and right parts of faces. Experiments were conducted on two benchmark datasets showing that our method achieved state-of-the-art performance, and ablation studies demonstrated the effectiveness of our method.