Learning Neural Volumetric Representations of Dynamic Humans in Minutes
{kind=link}
Abstract
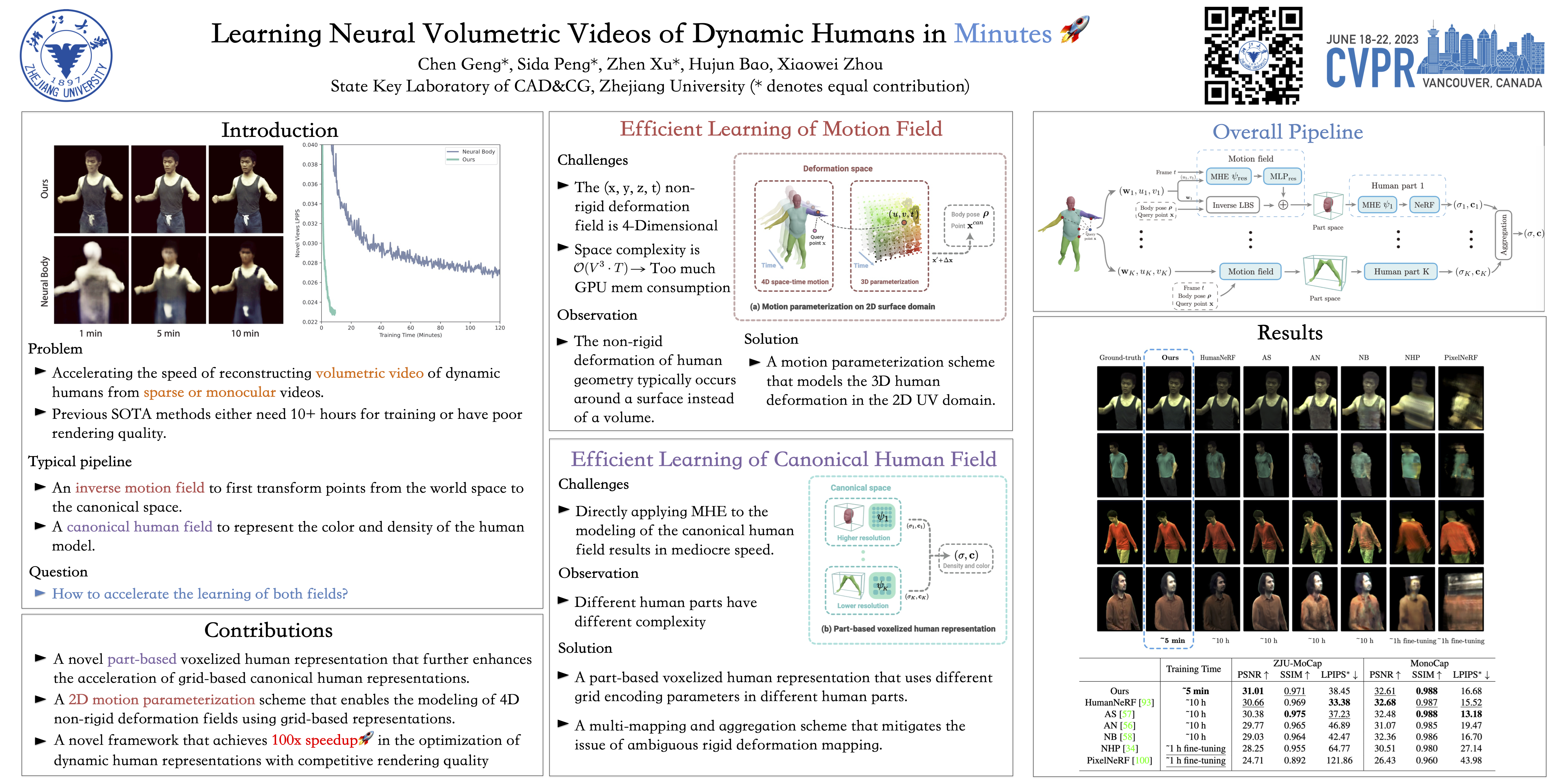
This paper addresses the challenge of efficiently reconstructing volumetric videos of dynamic humans from sparse multi-view videos. Some recent works represent a dynamic human as a canonical neural radiance field (NeRF) and a motion field, which are learned from input videos through differentiable rendering. But the per-scene optimization generally requires hours. Other generalizable NeRF models leverage learned prior from datasets to reduce the optimization time by only finetuning on new scenes at the cost of visual fidelity. In this paper, we propose a novel method for learning neural volumetric representations of dynamic humans in minutes with competitive visual quality. Specifically, we define a novel part-based voxelized human representation to better distribute the representational power of the network to different human parts. Furthermore, we propose a novel 2D motion parameterization scheme to increase the convergence rate of deformation field learning. Experiments demonstrate that our model can be learned 100 times faster than previous per-scene optimization methods while being competitive in the rendering quality. Training our model on a 512x512 video with 100 frames typically takes about 5 minutes on a single RTX 3090 GPU. The code is available on our project page: https://zju3dv.github.io/instant_nvr