PCR: Proxy-Based Contrastive Replay for Online Class-Incremental Continual Learning
{kind=link}
Abstract
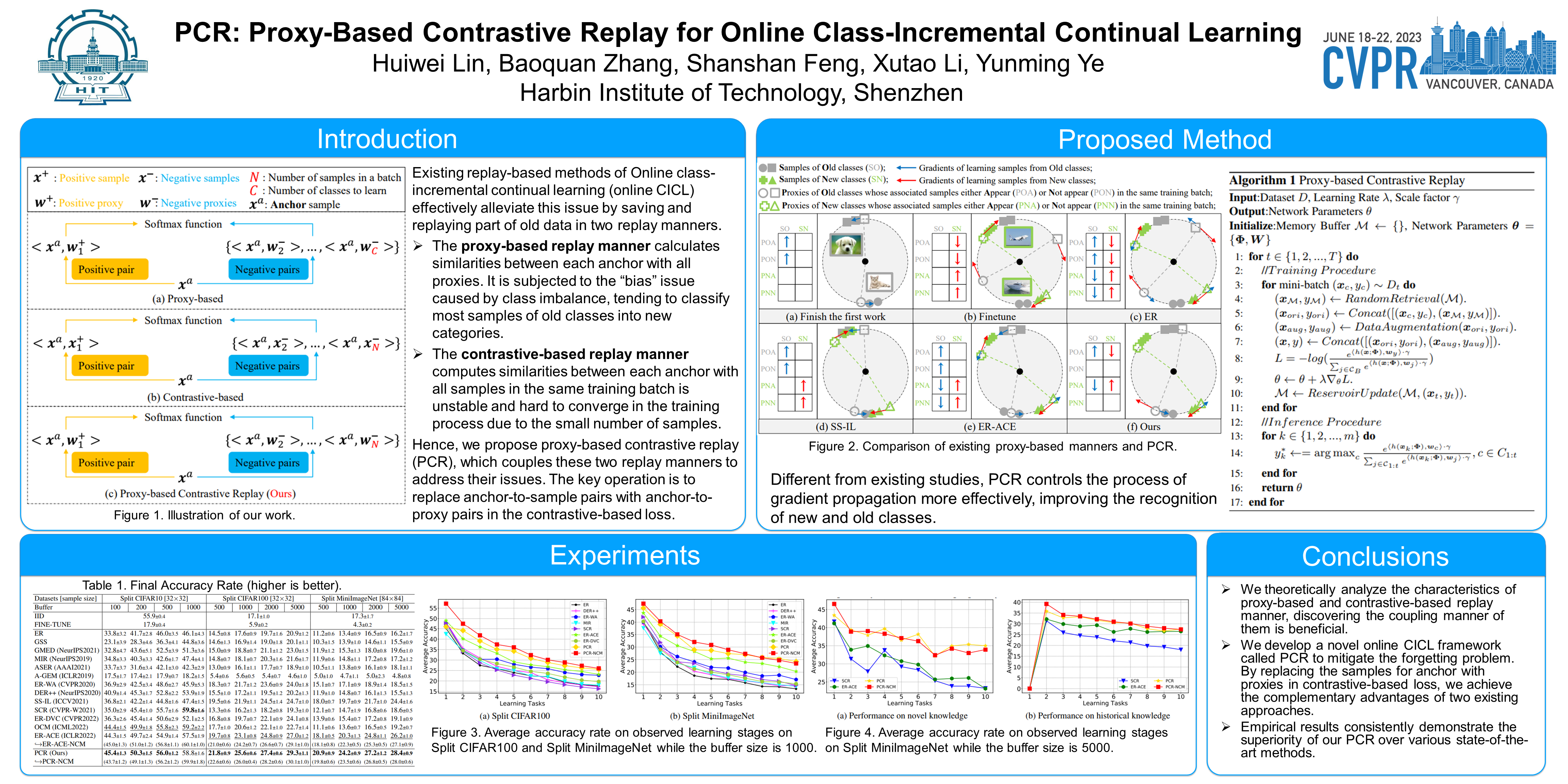
Online class-incremental continual learning is a specific task of continual learning. It aims to continuously learn new classes from data stream and the samples of data stream are seen only once, which suffers from the catastrophic forgetting issue, i.e., forgetting historical knowledge of old classes. Existing replay-based methods effectively alleviate this issue by saving and replaying part of old data in a proxy-based or contrastive-based replay manner. Although these two replay manners are effective, the former would incline to new classes due to class imbalance issues, and the latter is unstable and hard to converge because of the limited number of samples. In this paper, we conduct a comprehensive analysis of these two replay manners and find that they can be complementary. Inspired by this finding, we propose a novel replay-based method called proxy-based contrastive replay (PCR). The key operation is to replace the contrastive samples of anchors with corresponding proxies in the contrastive-based way. It alleviates the phenomenon of catastrophic forgetting by effectively addressing the imbalance issue, as well as keeps a faster convergence of the model. We conduct extensive experiments on three real-world benchmark datasets, and empirical results consistently demonstrate the superiority of PCR over various state-of-the-art methods.