SfM-TTR: Using Structure From Motion for Test-Time Refinement of Single-View Depth Networks
{kind=link}
Abstract
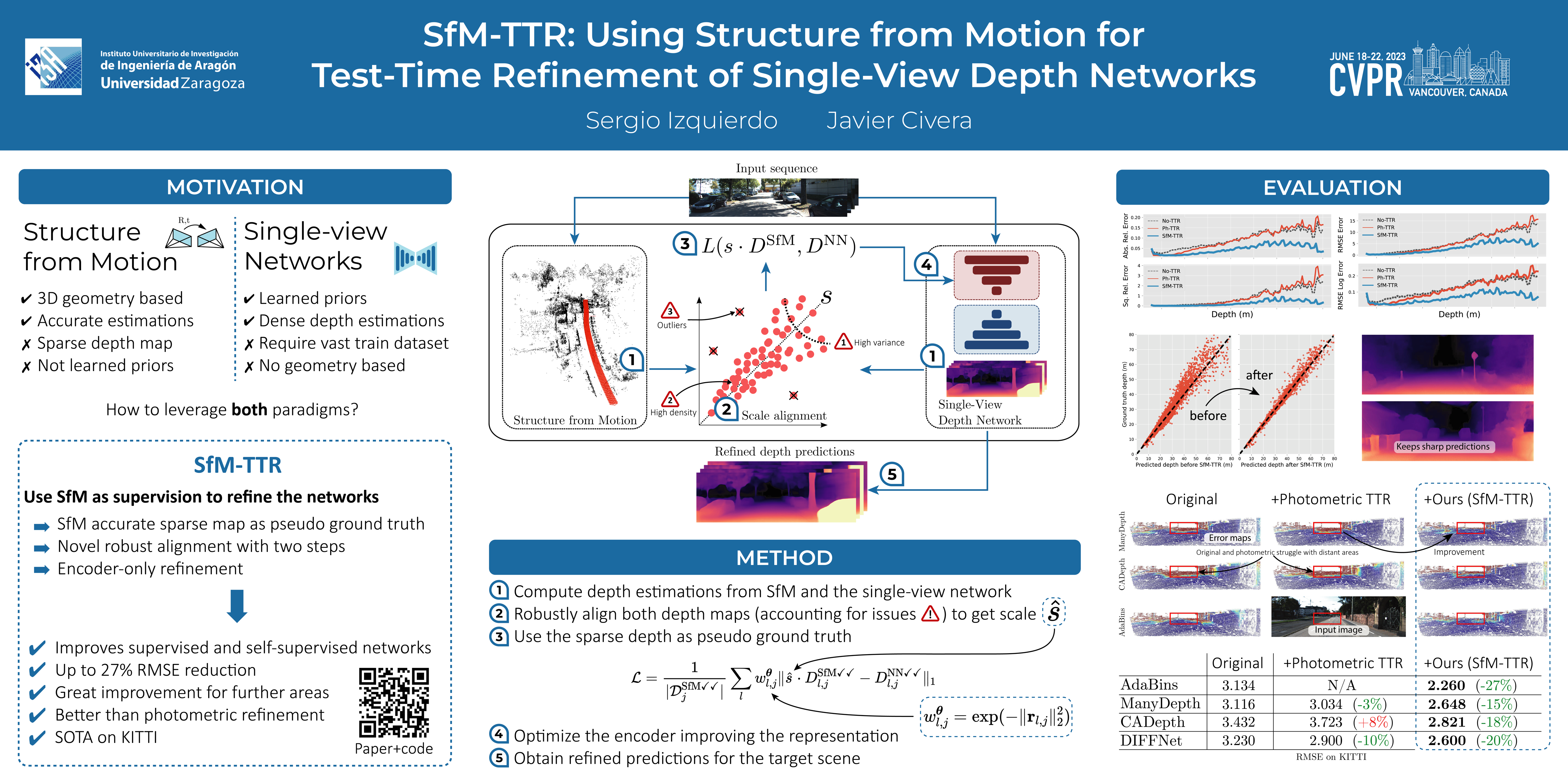
Estimating a dense depth map from a single view is geometrically ill-posed, and state-of-the-art methods rely on learning depth’s relation with visual appearance using deep neural networks. On the other hand, Structure from Motion (SfM) leverages multi-view constraints to produce very accurate but sparse maps, as matching across images is typically limited by locally discriminative texture. In this work, we combine the strengths of both approaches by proposing a novel test-time refinement (TTR) method, denoted as SfM-TTR, that boosts the performance of single-view depth networks at test time using SfM multi-view cues. Specifically, and differently from the state of the art, we use sparse SfM point clouds as test-time self-supervisory signal, fine-tuning the network encoder to learn a better representation of the test scene. Our results show how the addition of SfM-TTR to several state-of-the-art self-supervised and supervised networks improves significantly their performance, outperforming previous TTR baselines mainly based on photometric multi-view consistency. The code is available at https://github.com/serizba/SfM-TTR.