Lite-Mono: A Lightweight CNN and Transformer Architecture for Self-Supervised Monocular Depth Estimation
{kind=link}
Abstract
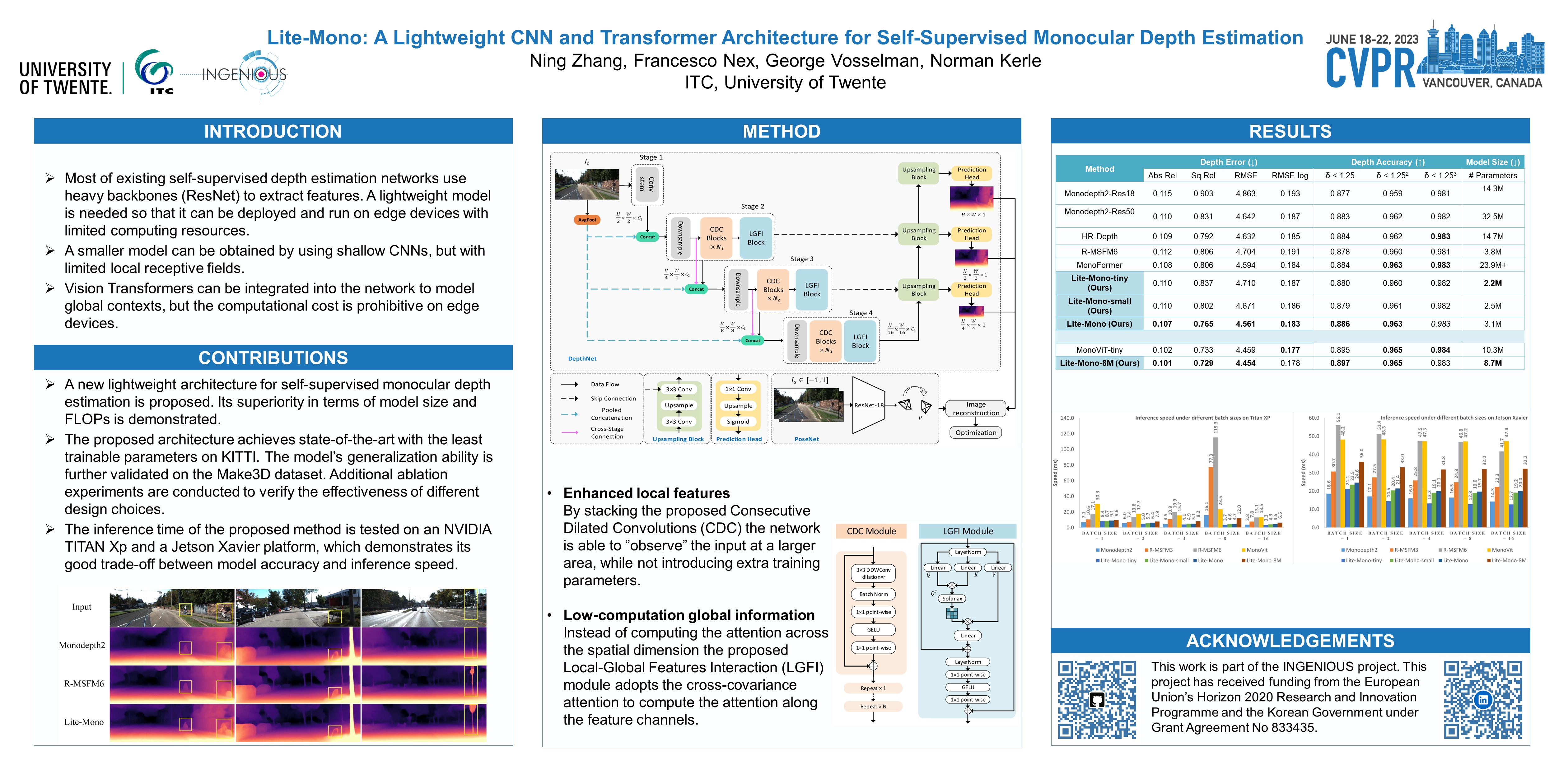
Self-supervised monocular depth estimation that does not require ground truth for training has attracted attention in recent years. It is of high interest to design lightweight but effective models so that they can be deployed on edge devices. Many existing architectures benefit from using heavier backbones at the expense of model sizes. This paper achieves comparable results with a lightweight architecture. Specifically, the efficient combination of CNNs and Transformers is investigated, and a hybrid architecture called Lite-Mono is presented. A Consecutive Dilated Convolutions (CDC) module and a Local-Global Features Interaction (LGFI) module are proposed. The former is used to extract rich multi-scale local features, and the latter takes advantage of the self-attention mechanism to encode long-range global information into the features. Experiments demonstrate that Lite-Mono outperforms Monodepth2 by a large margin in accuracy, with about 80% fewer trainable parameters. Our codes and models are available at https://github.com/noahzn/Lite-Mono.