Physics-Driven Diffusion Models for Impact Sound Synthesis From Videos
{kind=link}
Abstract
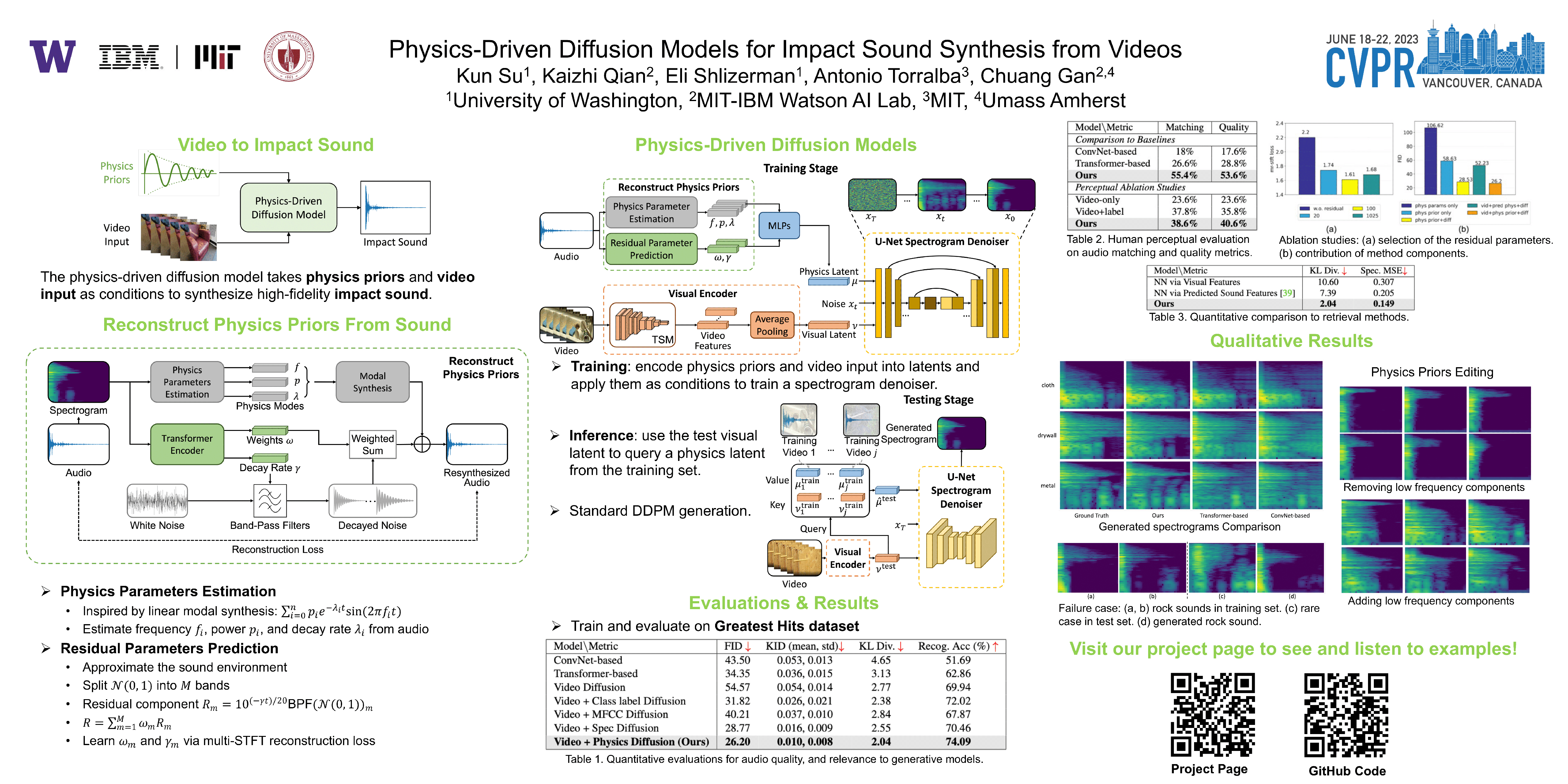
Modeling sounds emitted from physical object interactions is critical for immersive perceptual experiences in real and virtual worlds. Traditional methods of impact sound synthesis use physics simulation to obtain a set of physics parameters that could represent and synthesize the sound. However, they require fine details of both the object geometries and impact locations, which are rarely available in the real world and can not be applied to synthesize impact sounds from common videos. On the other hand, existing video-driven deep learning-based approaches could only capture the weak correspondence between visual content and impact sounds since they lack of physics knowledge. In this work, we propose a physics-driven diffusion model that can synthesize high-fidelity impact sound for a silent video clip. In addition to the video content, we propose to use additional physics priors to guide the impact sound synthesis procedure. The physics priors include both physics parameters that are directly estimated from noisy real-world impact sound examples without sophisticated setup and learned residual parameters that interpret the sound environment via neural networks. We further implement a novel diffusion model with specific training and inference strategies to combine physics priors and visual information for impact sound synthesis. Experimental results show that our model outperforms several existing systems in generating realistic impact sounds. More importantly, the physics-based representations are fully interpretable and transparent, thus enabling us to perform sound editing flexibly. We encourage the readers to visit our project page to watch demo videos with audio turned on to experience the results.