An Image Quality Assessment Dataset for Portraits
{kind=link}
Abstract
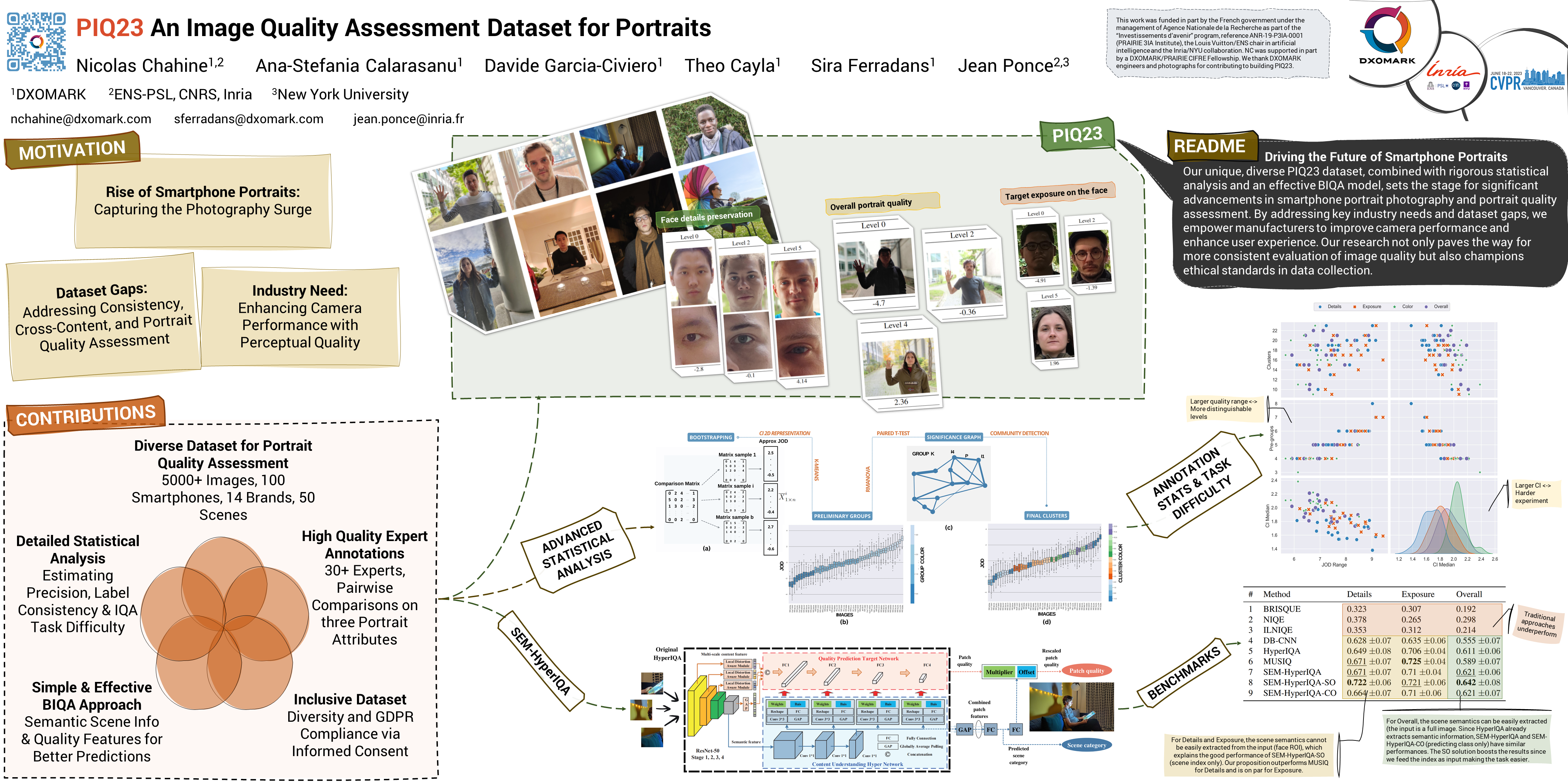
Year after year, the demand for ever-better smartphone photos continues to grow, in particular in the domain of portrait photography. Manufacturers thus use perceptual quality criteria throughout the development of smartphone cameras. This costly procedure can be partially replaced by automated learning-based methods for image quality assessment (IQA). Due to its subjective nature, it is necessary to estimate and guarantee the consistency of the IQA process, a characteristic lacking in the mean opinion scores (MOS) widely used for crowdsourcing IQA. In addition, existing blind IQA (BIQA) datasets pay little attention to the difficulty of cross-content assessment, which may degrade the quality of annotations. This paper introduces PIQ23, a portrait-specific IQA dataset of 5116 images of 50 predefined scenarios acquired by 100 smartphones, covering a high variety of brands, models, and use cases. The dataset includes individuals of various genders and ethnicities who have given explicit and informed consent for their photographs to be used in public research. It is annotated by pairwise comparisons (PWC) collected from over 30 image quality experts for three image attributes: face detail preservation, face target exposure, and overall image quality. An in-depth statistical analysis of these annotations allows us to evaluate their consistency over PIQ23. Finally, we show through an extensive comparison with existing baselines that semantic information (image context) can be used to improve IQA predictions.