Noisy Correspondence Learning With Meta Similarity Correction
{kind=link}
Abstract
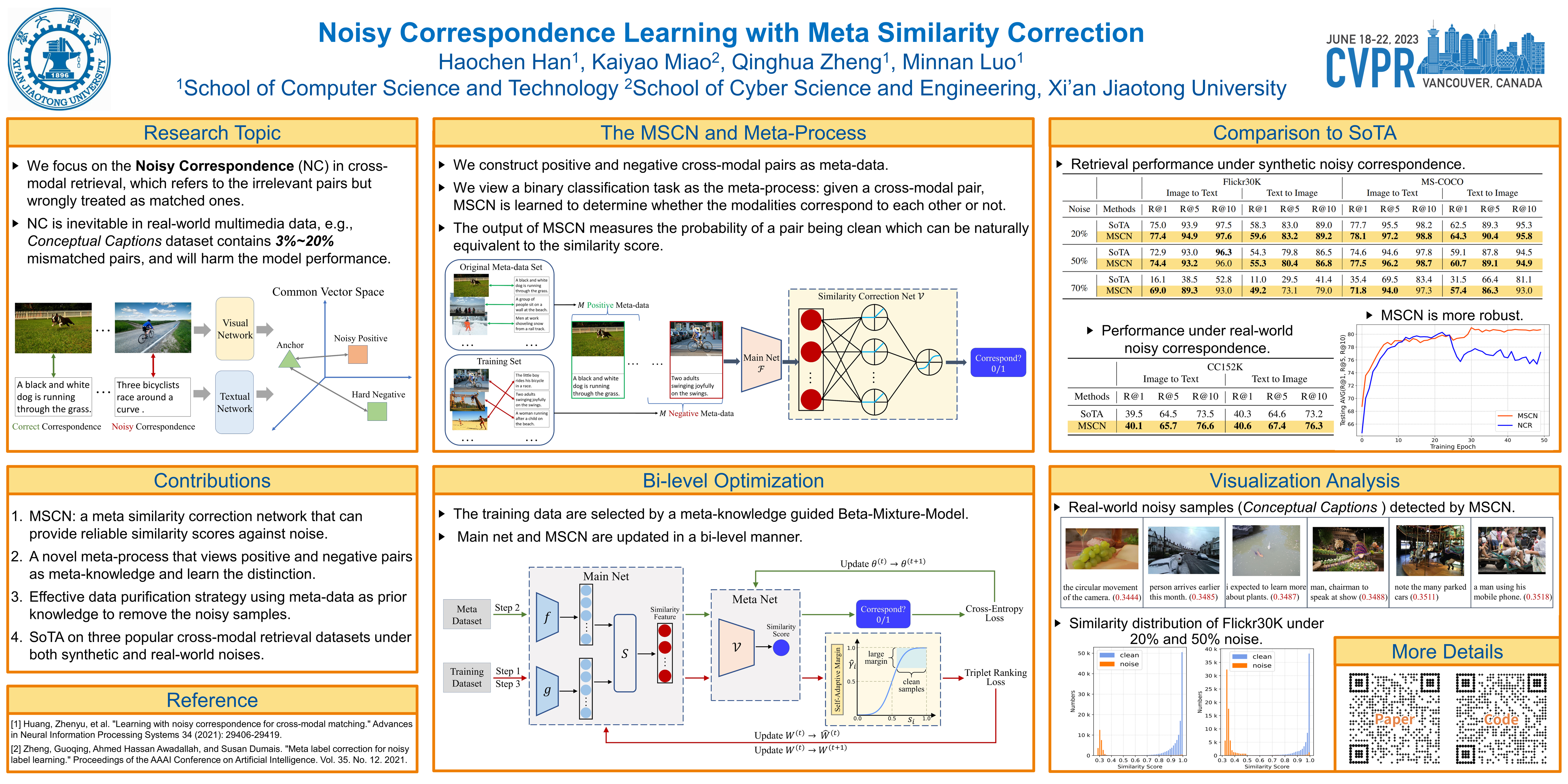
Despite the success of multimodal learning in cross-modal retrieval task, the remarkable progress relies on the correct correspondence among multimedia data. However, collecting such ideal data is expensive and time-consuming. In practice, most widely used datasets are harvested from the Internet and inevitably contain mismatched pairs. Training on such noisy correspondence datasets causes performance degradation because the cross-modal retrieval methods can wrongly enforce the mismatched data to be similar. To tackle this problem, we propose a Meta Similarity Correction Network (MSCN) to provide reliable similarity scores. We view a binary classification task as the meta-process that encourages the MSCN to learn discrimination from positive and negative meta-data. To further alleviate the influence of noise, we design an effective data purification strategy using meta-data as prior knowledge to remove the noisy samples. Extensive experiments are conducted to demonstrate the strengths of our method in both synthetic and real-world noises, including Flickr30K, MS-COCO, and Conceptual Captions.