Delving StyleGAN Inversion for Image Editing: A Foundation Latent Space Viewpoint
{kind=link}
Abstract
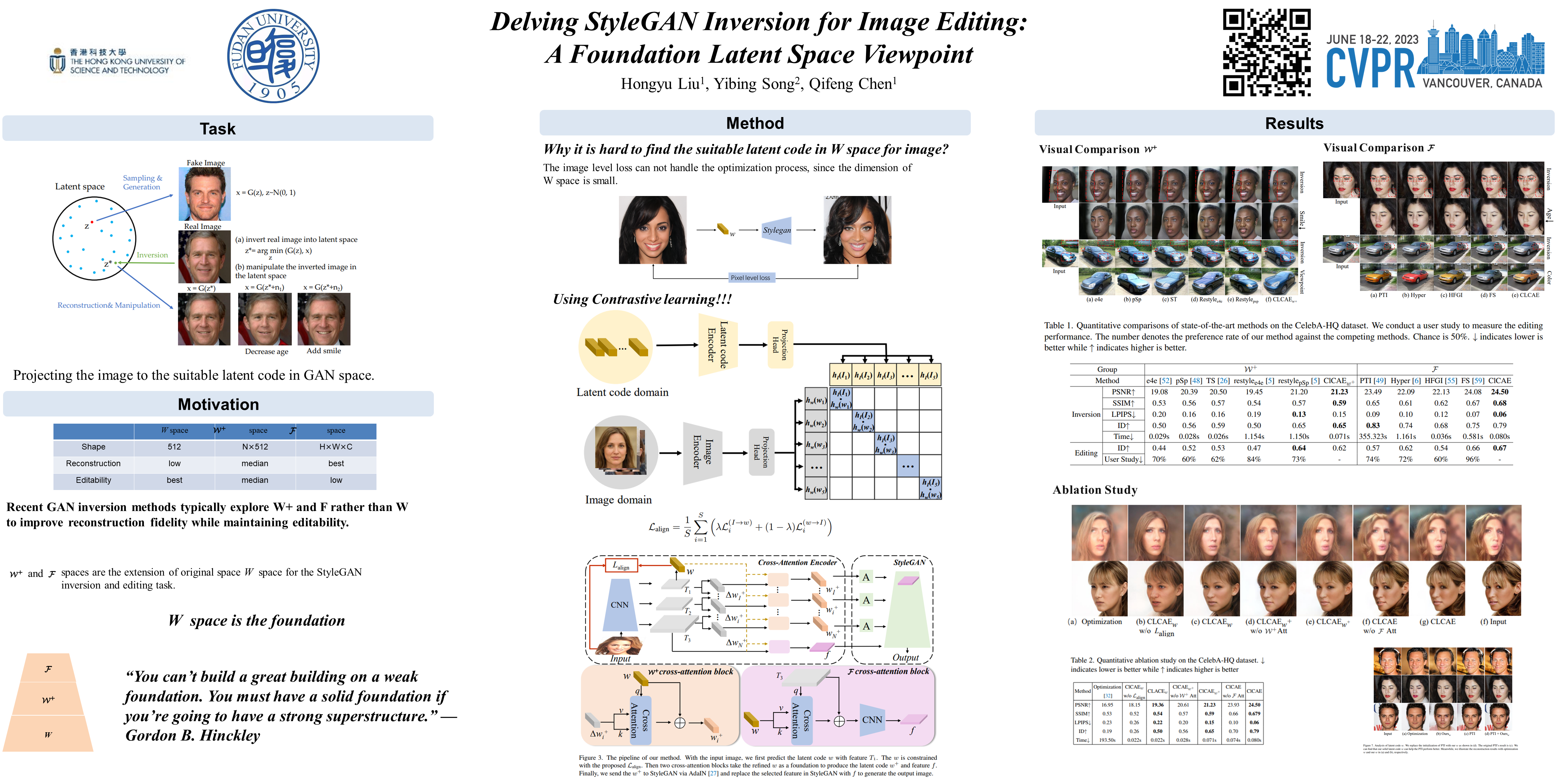
GAN inversion and editing via StyleGAN maps an input image into the embedding spaces (W, W^+, and F) to simultaneously maintain image fidelity and meaningful manipulation. From latent space W to extended latent space W^+ to feature space F in StyleGAN, the editability of GAN inversion decreases while its reconstruction quality increases. Recent GAN inversion methods typically explore W^+ and F rather than W to improve reconstruction fidelity while maintaining editability. As W^+ and F are derived from W that is essentially the foundation latent space of StyleGAN, these GAN inversion methods focusing on W^+ and F spaces could be improved by stepping back to W. In this work, we propose to first obtain the proper latent code in foundation latent space W. We introduce contrastive learning to align W and the image space for proper latent code discovery. Then, we leverage a cross-attention encoder to transform the obtained latent code in W into W^+ and F, accordingly. Our experiments show that our exploration of the foundation latent space W improves the representation ability of latent codes in W^+ and features in F, which yields state-of-the-art reconstruction fidelity and editability results on the standard benchmarks. Project page: https://kumapowerliu.github.io/CLCAE.