Target-Referenced Reactive Grasping for Dynamic Objects
{kind=link}
Abstract
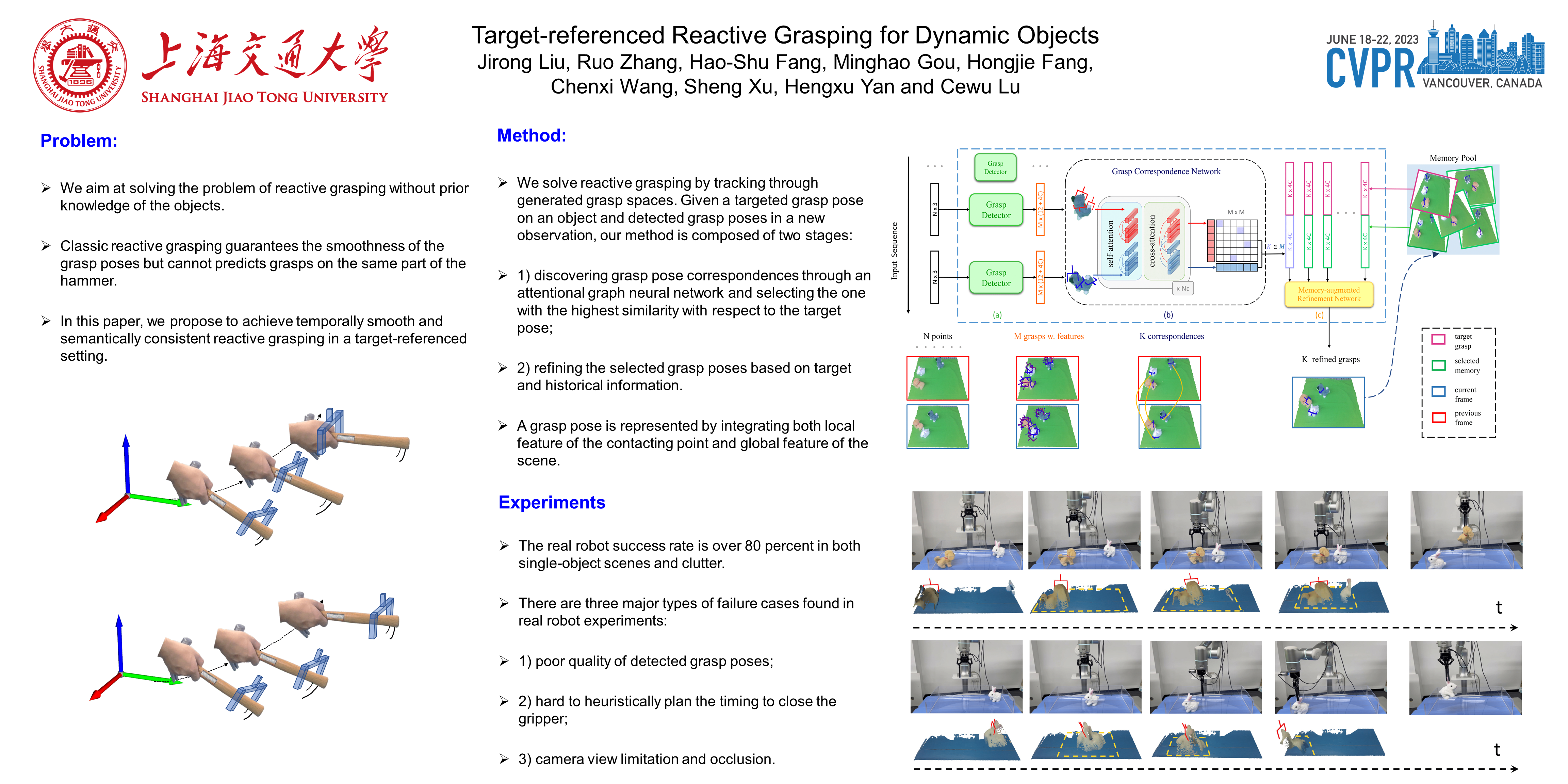
Reactive grasping, which enables the robot to successfully grasp dynamic moving objects, is of great interest in robotics. Current methods mainly focus on the temporal smoothness of the predicted grasp poses but few consider their semantic consistency. Consequently, the predicted grasps are not guaranteed to fall on the same part of the same object, especially in cluttered scenes. In this paper, we propose to solve reactive grasping in a target-referenced setting by tracking through generated grasp spaces. Given a targeted grasp pose on an object and detected grasp poses in a new observation, our method is composed of two stages: 1) discovering grasp pose correspondences through an attentional graph neural network and selecting the one with the highest similarity with respect to the target pose; 2) refining the selected grasp poses based on target and historical information. We evaluate our method on a large-scale benchmark GraspNet-1Billion. We also collect 30 scenes of dynamic objects for testing. The results suggest that our method outperforms other representative methods. Furthermore, our real robot experiments achieve an average success rate of over 80 percent.