Exploiting Unlabelled Photos for Stronger Fine-Grained SBIR
{kind=link}
Abstract
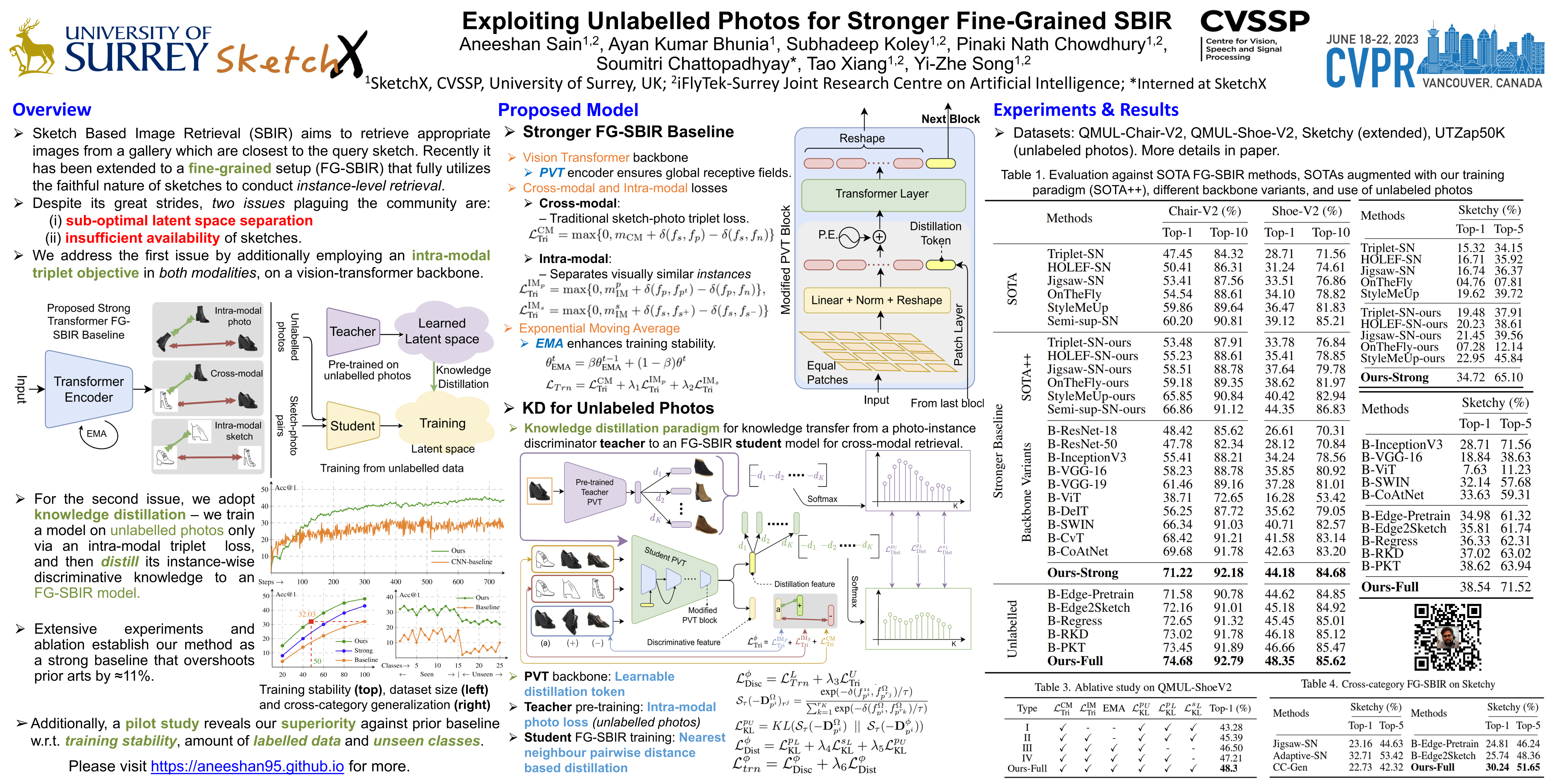
This paper advances the fine-grained sketch-based image retrieval (FG-SBIR) literature by putting forward a strong baseline that overshoots prior state-of-the art by ~11%. This is not via complicated design though, but by addressing two critical issues facing the community (i) the gold standard triplet loss does not enforce holistic latent space geometry, and (ii) there are never enough sketches to train a high accuracy model. For the former, we propose a simple modification to the standard triplet loss, that explicitly enforces separation amongst photos/sketch instances. For the latter, we put forward a novel knowledge distillation module can leverage photo data for model training. Both modules are then plugged into a novel plug-n-playable training paradigm that allows for more stable training. More specifically, for (i) we employ an intra-modal triplet loss amongst sketches to bring sketches of the same instance closer from others, and one more amongst photos to push away different photo instances while bringing closer a structurally augmented version of the same photo (offering a gain of 4-6%). To tackle (ii), we first pre-train a teacher on the large set of unlabelled photos over the aforementioned intra-modal photo triplet loss. Then we distill the contextual similarity present amongst the instances in the teacher’s embedding space to that in the student’s embedding space, by matching the distribution over inter-feature distances of respective samples in both embedding spaces (delivering a further gain of 4-5%). Apart from outperforming prior arts significantly, our model also yields satisfactory results on generalising to new classes. Project page: https://aneeshan95.github.io/Sketch_PVT/