Feature Aggregated Queries for Transformer-Based Video Object Detectors
{kind=link}
Abstract
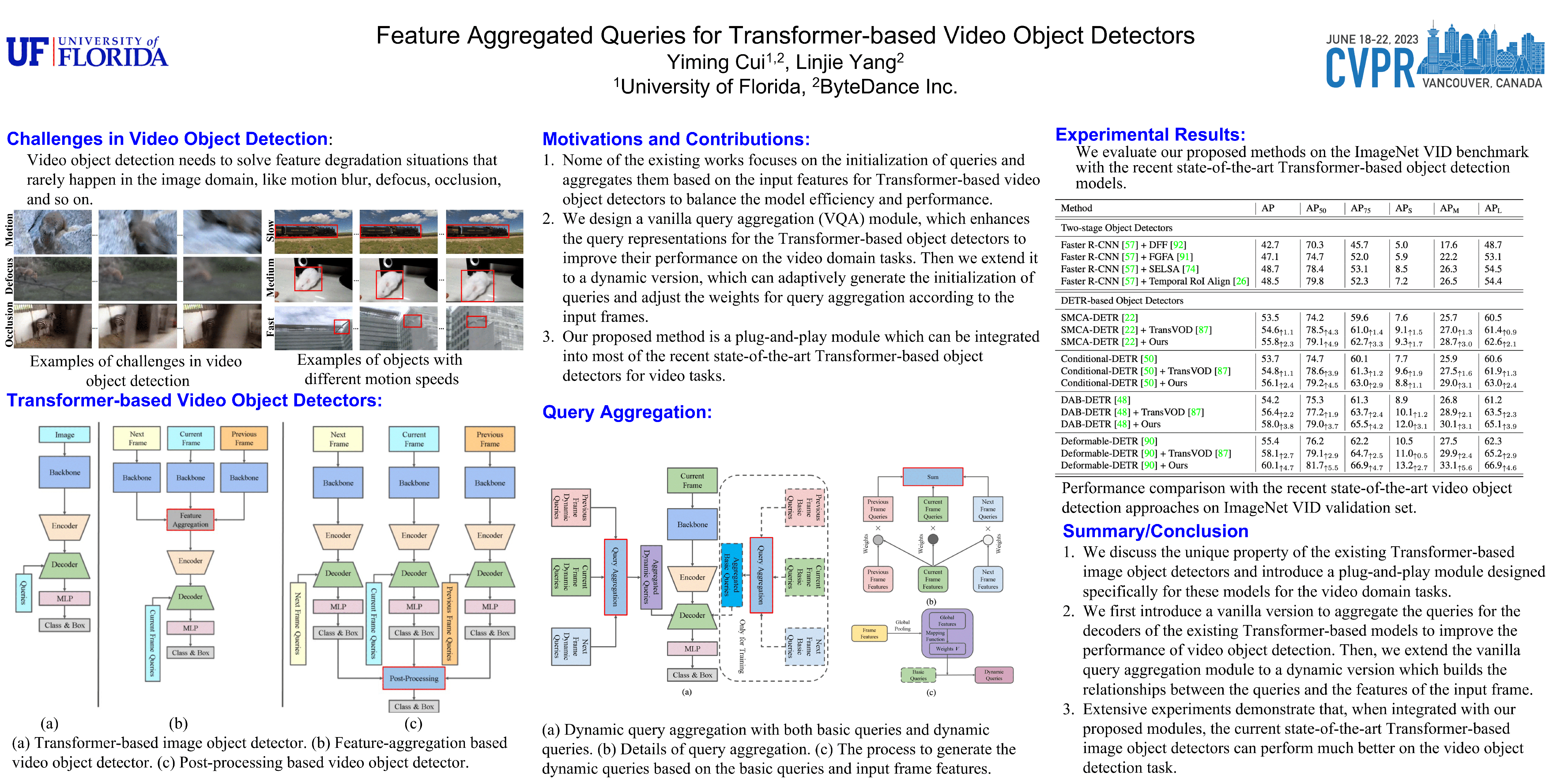
Video object detection needs to solve feature degradation situations that rarely happen in the image domain. One solution is to use the temporal information and fuse the features from the neighboring frames. With Transformer-based object detectors getting a better performance on the image domain tasks, recent works began to extend those methods to video object detection. However, those existing Transformer-based video object detectors still follow the same pipeline as those used for classical object detectors, like enhancing the object feature representations by aggregation. In this work, we take a different perspective on video object detection. In detail, we improve the qualities of queries for the Transformer-based models by aggregation. To achieve this goal, we first propose a vanilla query aggregation module that weighted averages the queries according to the features of the neighboring frames. Then, we extend the vanilla module to a more practical version, which generates and aggregates queries according to the features of the input frames. Extensive experimental results validate the effectiveness of our proposed methods: On the challenging ImageNet VID benchmark, when integrated with our proposed modules, the current state-of-the-art Transformer-based object detectors can be improved by more than 2.4% on mAP and 4.2% on AP50.