Shepherding Slots to Objects: Towards Stable and Robust Object-Centric Learning
{kind=link}
Abstract
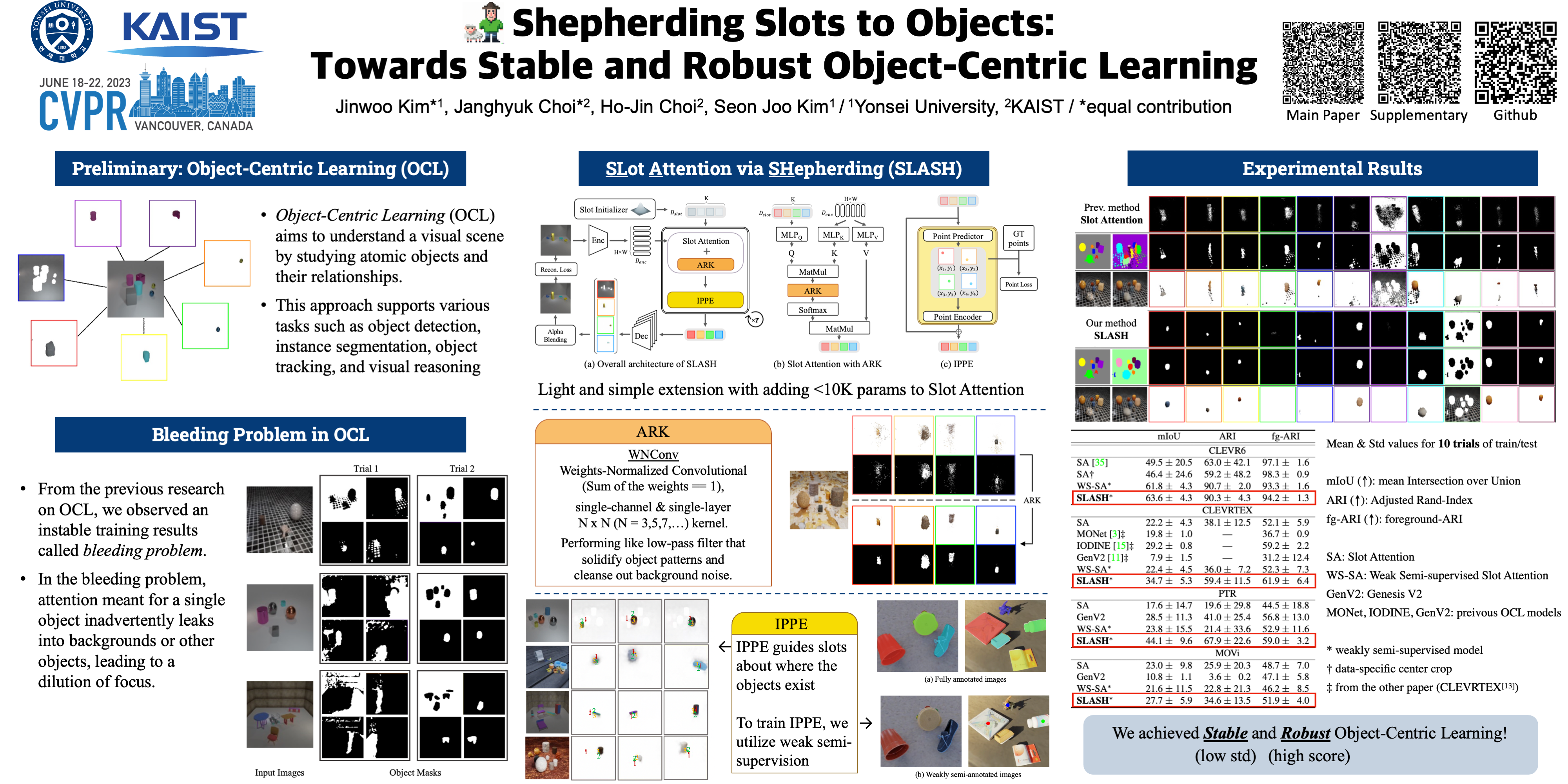
Object-centric learning (OCL) aspires general and com- positional understanding of scenes by representing a scene as a collection of object-centric representations. OCL has also been extended to multi-view image and video datasets to apply various data-driven inductive biases by utilizing geometric or temporal information in the multi-image data. Single-view images carry less information about how to disentangle a given scene than videos or multi-view im- ages do. Hence, owing to the difficulty of applying induc- tive biases, OCL for single-view images still remains chal- lenging, resulting in inconsistent learning of object-centric representation. To this end, we introduce a novel OCL framework for single-view images, SLot Attention via SHep- herding (SLASH), which consists of two simple-yet-effective modules on top of Slot Attention. The new modules, At- tention Refining Kernel (ARK) and Intermediate Point Pre- dictor and Encoder (IPPE), respectively, prevent slots from being distracted by the background noise and indicate lo- cations for slots to focus on to facilitate learning of object- centric representation. We also propose a weak- and semi- supervision approach for OCL, whilst our proposed frame- work can be used without any assistant annotation during the inference. Experiments show that our proposed method enables consistent learning of object-centric representa- tion and achieves strong performance across four datasets. Code is available at https://github.com/object- understanding/SLASH.