PivoTAL: Prior-Driven Supervision for Weakly-Supervised Temporal Action Localization
{kind=link}
Abstract
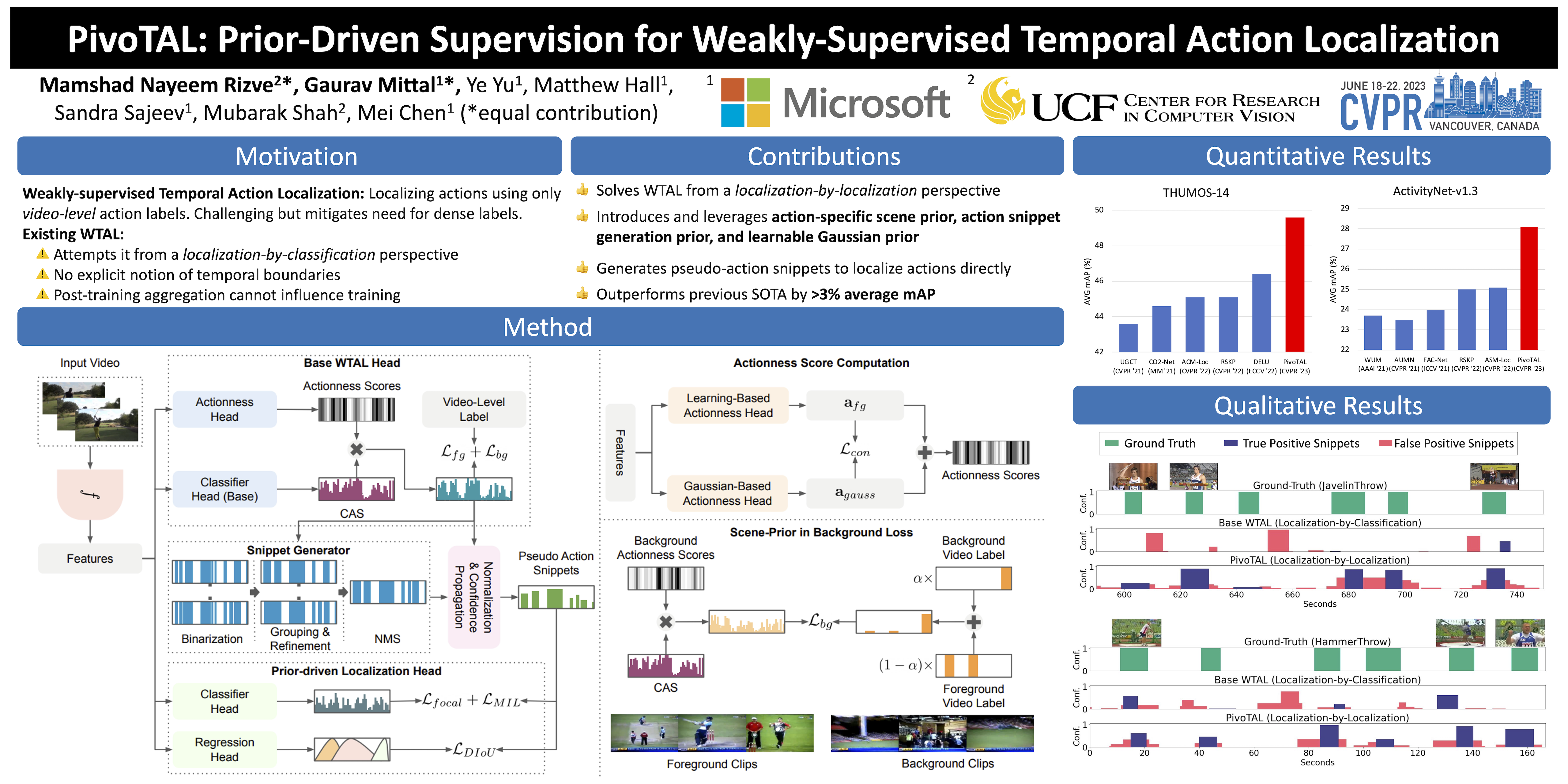
Weakly-supervised Temporal Action Localization (WTAL) attempts to localize the actions in untrimmed videos using only video-level supervision. Most recent works approach WTAL from a localization-by-classification perspective where these methods try to classify each video frame followed by a manually-designed post-processing pipeline to aggregate these per-frame action predictions into action snippets. Due to this perspective, the model lacks any explicit understanding of action boundaries and tends to focus only on the most discriminative parts of the video resulting in incomplete action localization. To address this, we present PivoTAL, Prior-driven Supervision for Weakly-supervised Temporal Action Localization, to approach WTAL from a localization-by-localization perspective by learning to localize the action snippets directly. To this end, PivoTAL leverages the underlying spatio-temporal regularities in videos in the form of action-specific scene prior, action snippet generation prior, and learnable Gaussian prior to supervise the localization-based training. PivoTAL shows significant improvement (of at least 3% avg mAP) over all existing methods on the benchmark datasets, THUMOS-14 and ActivitNet-v1.3.