Mofusion: A Framework for Denoising-Diffusion-Based Motion Synthesis
 Highlight
Highlight
{kind=link}
Abstract
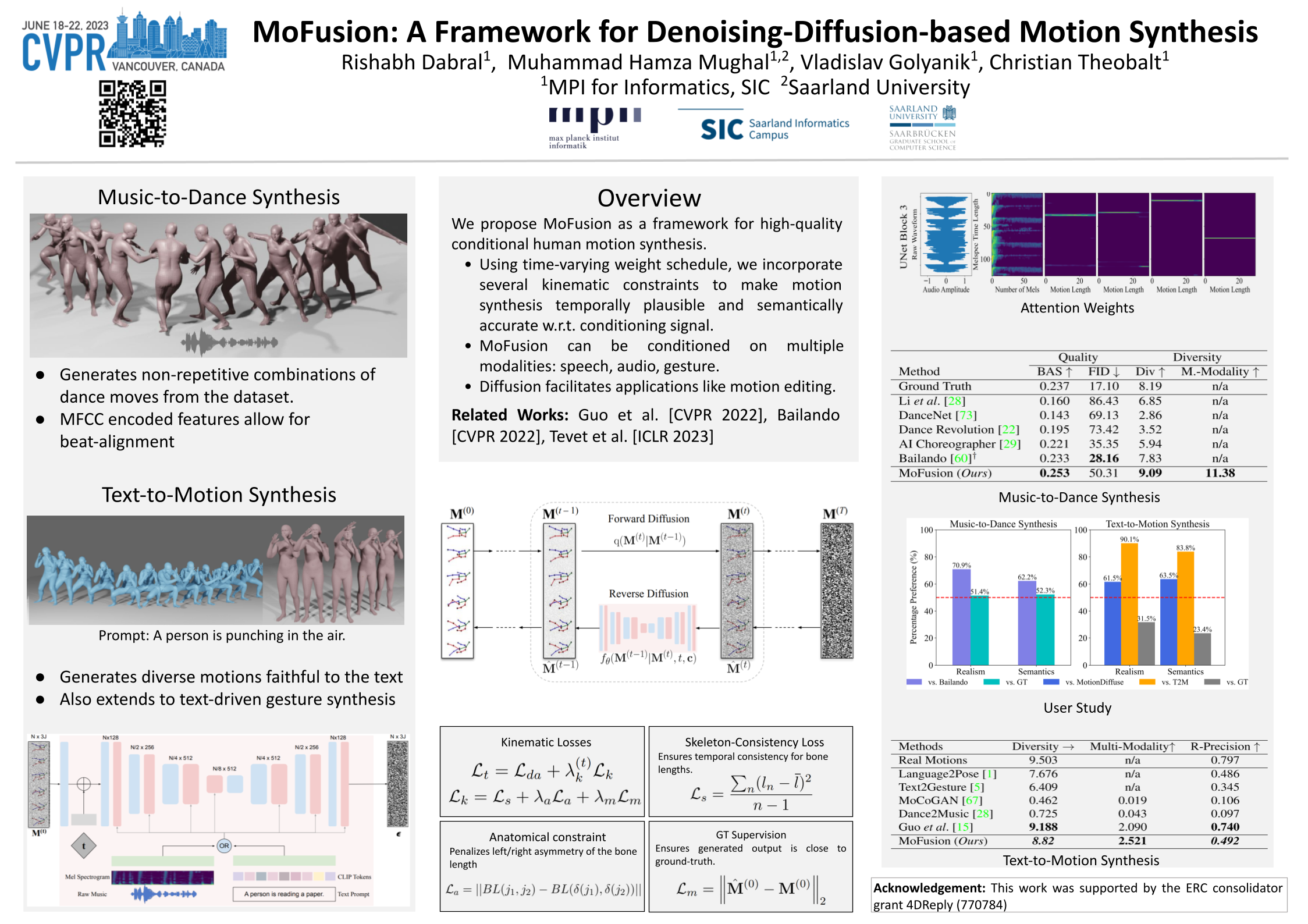
Conventional methods for human motion synthesis have either been deterministic or have had to struggle with the trade-off between motion diversity vs~motion quality. In response to these limitations, we introduce MoFusion, i.e., a new denoising-diffusion-based framework for high-quality conditional human motion synthesis that can synthesise long, temporally plausible, and semantically accurate motions based on a range of conditioning contexts (such as music and text). We also present ways to introduce well-known kinematic losses for motion plausibility within the motion-diffusion framework through our scheduled weighting strategy. The learned latent space can be used for several interactive motion-editing applications like in-betweening, seed-conditioning, and text-based editing, thus, providing crucial abilities for virtual-character animation and robotics. Through comprehensive quantitative evaluations and a perceptual user study, we demonstrate the effectiveness of MoFusion compared to the state-of-the-art on established benchmarks in the literature. We urge the reader to watch our supplementary video. The source code will be released.