Initialization Noise in Image Gradients and Saliency Maps
{kind=link}
Abstract
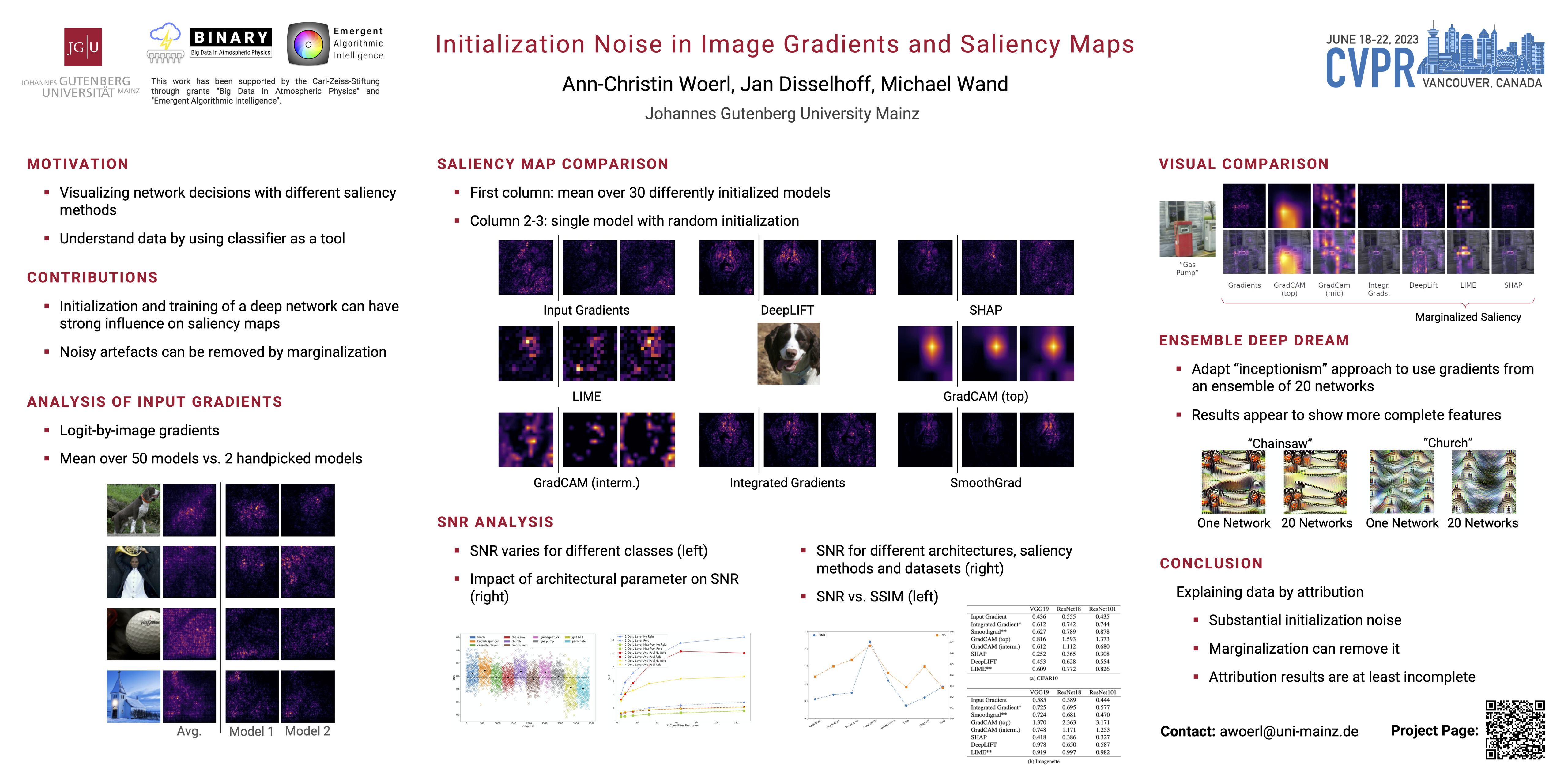
In this paper, we examine gradients of logits of image classification CNNs by input pixel values. We observe that these fluctuate considerably with training randomness, such as the random initialization of the networks. We extend our study to gradients of intermediate layers, obtained via GradCAM, as well as popular network saliency estimators such as DeepLIFT, SHAP, LIME, Integrated Gradients, and SmoothGrad. While empirical noise levels vary, qualitatively different attributions to image features are still possible with all of these, which comes with implications for interpreting such attributions, in particular when seeking data-driven explanations of the phenomenon generating the data. Finally, we demonstrate that the observed artefacts can be removed by marginalization over the initialization distribution by simple stochastic integration.