Task Residual for Tuning Vision-Language Models
{kind=link}
Abstract
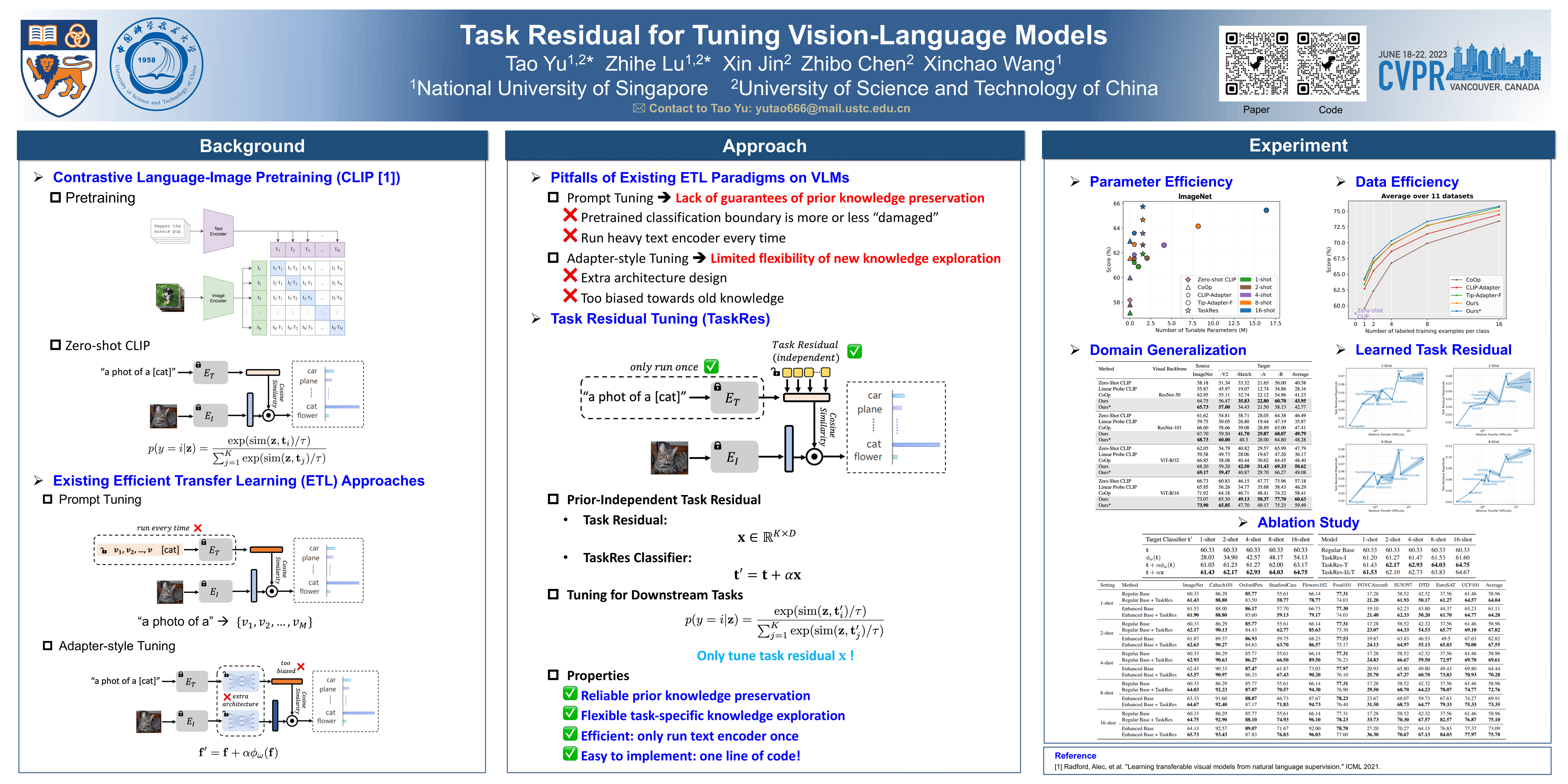
Large-scale vision-language models (VLMs) pre-trained on billion-level data have learned general visual representations and broad visual concepts. In principle, the well-learned knowledge structure of the VLMs should be inherited appropriately when being transferred to downstream tasks with limited data. However, most existing efficient transfer learning (ETL) approaches for VLMs either damage or are excessively biased towards the prior knowledge, e.g., prompt tuning (PT) discards the pre-trained text-based classifier and builds a new one while adapter-style tuning (AT) fully relies on the pre-trained features. To address this, we propose a new efficient tuning approach for VLMs named Task Residual Tuning (TaskRes), which performs directly on the text-based classifier and explicitly decouples the prior knowledge of the pre-trained models and new knowledge regarding a target task. Specifically, TaskRes keeps the original classifier weights from the VLMs frozen and obtains a new classifier for the target task by tuning a set of prior-independent parameters as a residual to the original one, which enables reliable prior knowledge preservation and flexible task-specific knowledge exploration. The proposed TaskRes is simple yet effective, which significantly outperforms previous ETL methods (e.g., PT and AT) on 11 benchmark datasets while requiring minimal effort for the implementation. Our code is available at https://github.com/geekyutao/TaskRes.