Revisiting Self-Similarity: Structural Embedding for Image Retrieval
{kind=link}
Abstract
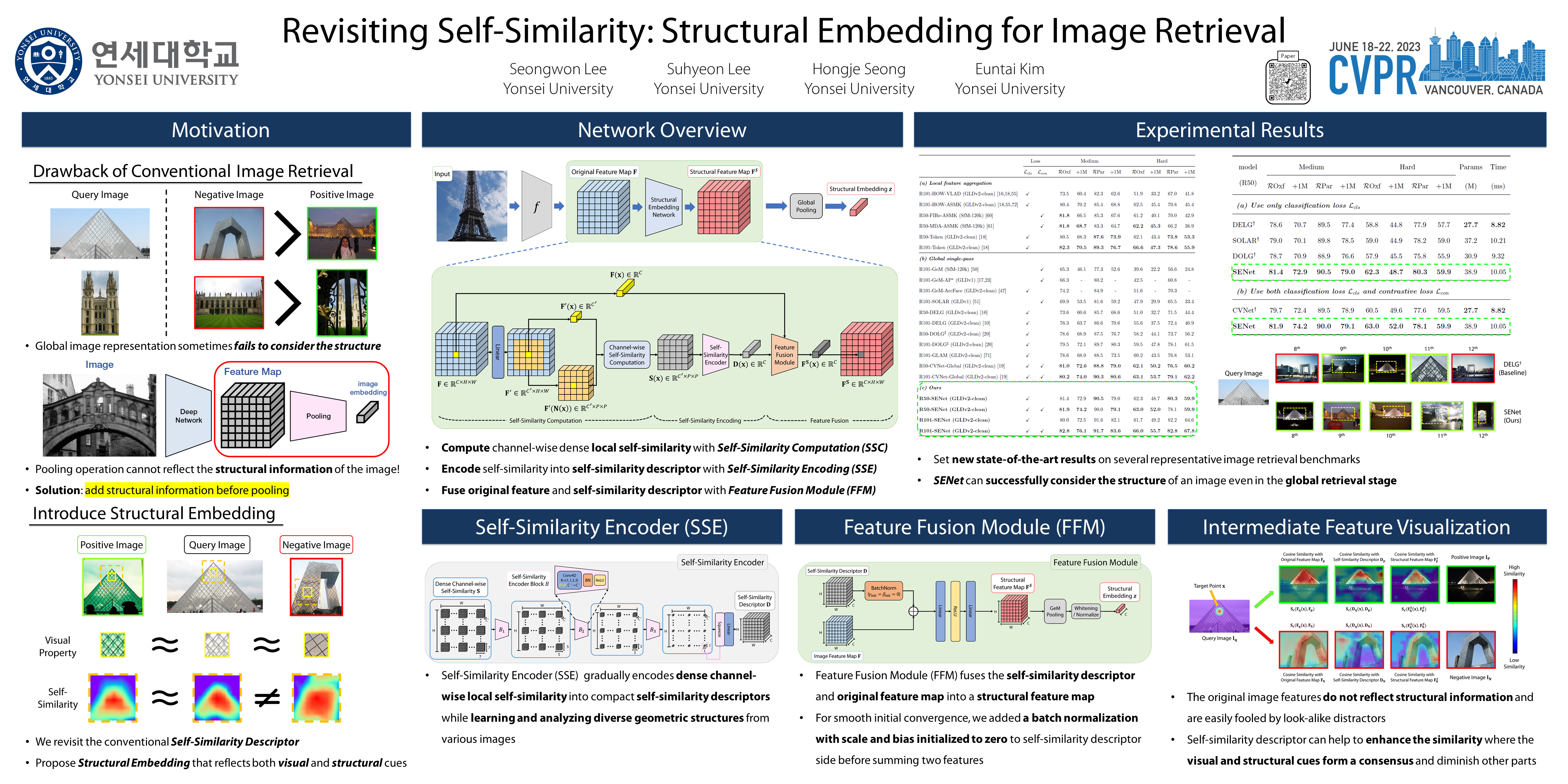
Despite advances in global image representation, existing image retrieval approaches rarely consider geometric structure during the global retrieval stage. In this work, we revisit the conventional self-similarity descriptor from a convolutional perspective, to encode both the visual and structural cues of the image to global image representation. Our proposed network, named Structural Embedding Network (SENet), captures the internal structure of the images and gradually compresses them into dense self-similarity descriptors while learning diverse structures from various images. These self-similarity descriptors and original image features are fused and then pooled into global embedding, so that global embedding can represent both geometric and visual cues of the image. Along with this novel structural embedding, our proposed network sets new state-of-the-art performances on several image retrieval benchmarks, convincing its robustness to look-alike distractors. The code and models are available: https://github.com/sungonce/SENet.