PSVT: End-to-End Multi-Person 3D Pose and Shape Estimation With Progressive Video Transformers
{kind=link}
Abstract
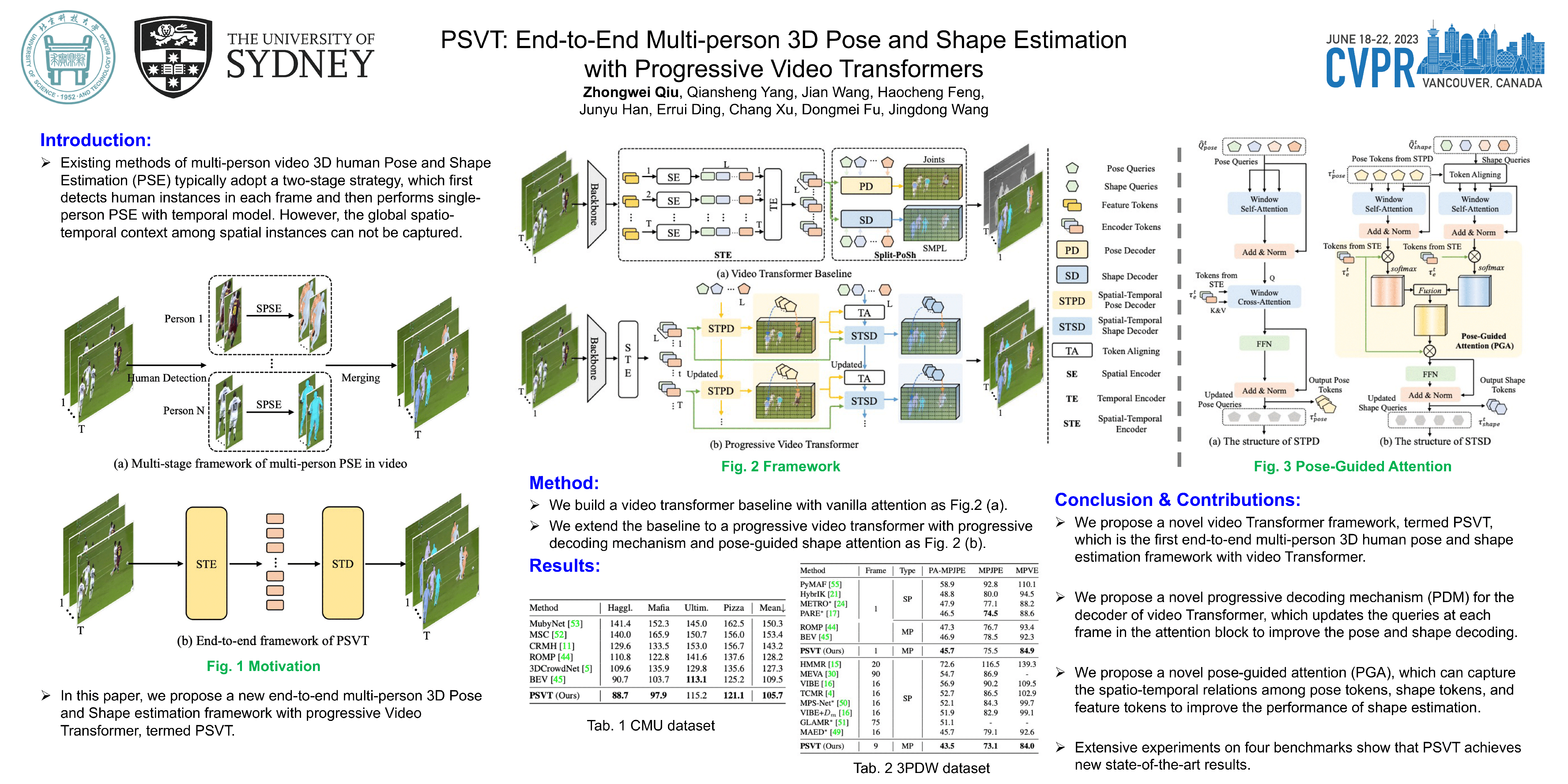
Existing methods of multi-person video 3D human Pose and Shape Estimation (PSE) typically adopt a two-stage strategy, which first detects human instances in each frame and then performs single-person PSE with temporal model. However, the global spatio-temporal context among spatial instances can not be captured. In this paper, we propose a new end-to-end multi-person 3D Pose and Shape estimation framework with progressive Video Transformer, termed PSVT. In PSVT, a spatio-temporal encoder (STE) captures the global feature dependencies among spatial objects. Then, spatio-temporal pose decoder (STPD) and shape decoder (STSD) capture the global dependencies between pose queries and feature tokens, shape queries and feature tokens, respectively. To handle the variances of objects as time proceeds, a novel scheme of progressive decoding is used to update pose and shape queries at each frame. Besides, we propose a novel pose-guided attention (PGA) for shape decoder to better predict shape parameters. The two components strengthen the decoder of PSVT to improve performance. Extensive experiments on the four datasets show that PSVT achieves stage-of-the-art results.