Think Twice Before Driving: Towards Scalable Decoders for End-to-End Autonomous Driving
{kind=link}
Abstract
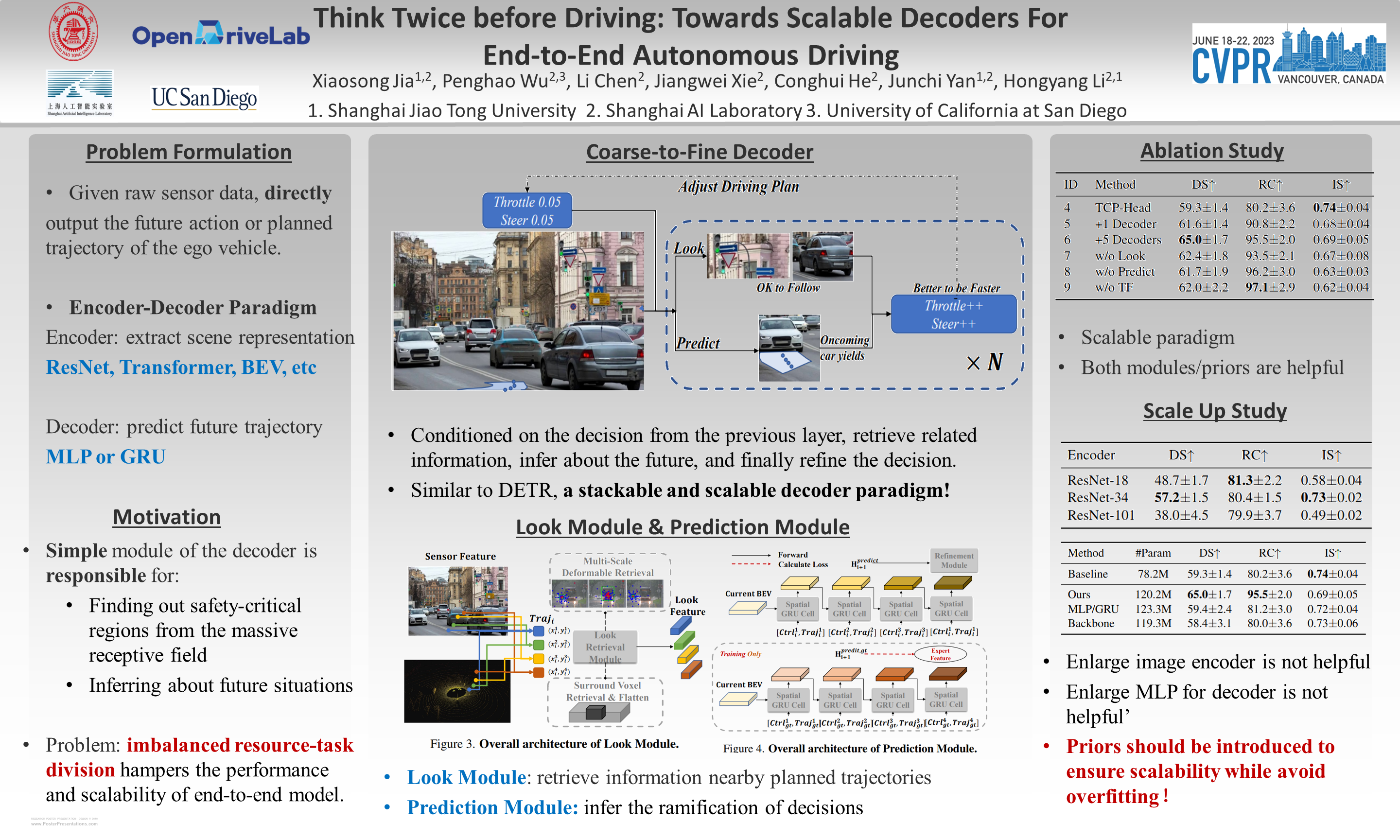
End-to-end autonomous driving has made impressive progress in recent years. Existing methods usually adopt the decoupled encoder-decoder paradigm, where the encoder extracts hidden features from raw sensor data, and the decoder outputs the ego-vehicle’s future trajectories or actions. Under such a paradigm, the encoder does not have access to the intended behavior of the ego agent, leaving the burden of finding out safety-critical regions from the massive receptive field and inferring about future situations to the decoder. Even worse, the decoder is usually composed of several simple multi-layer perceptrons (MLP) or GRUs while the encoder is delicately designed (e.g., a combination of heavy ResNets or Transformer). Such an imbalanced resource-task division hampers the learning process. In this work, we aim to alleviate the aforementioned problem by two principles: (1) fully utilizing the capacity of the encoder; (2) increasing the capacity of the decoder. Concretely, we first predict a coarse-grained future position and action based on the encoder features. Then, conditioned on the position and action, the future scene is imagined to check the ramification if we drive accordingly. We also retrieve the encoder features around the predicted coordinate to obtain fine-grained information about the safety-critical region. Finally, based on the predicted future and the retrieved salient feature, we refine the coarse-grained position and action by predicting its offset from ground-truth. The above refinement module could be stacked in a cascaded fashion, which extends the capacity of the decoder with spatial-temporal prior knowledge about the conditioned future. We conduct experiments on the CARLA simulator and achieve state-of-the-art performance in closed-loop benchmarks. Extensive ablation studies demonstrate the effectiveness of each proposed module. Code and models are available at https://github.com/opendrivelab/ThinkTwice.