Dionysus: Recovering Scene Structures by Dividing Into Semantic Pieces
{kind=link}
Abstract
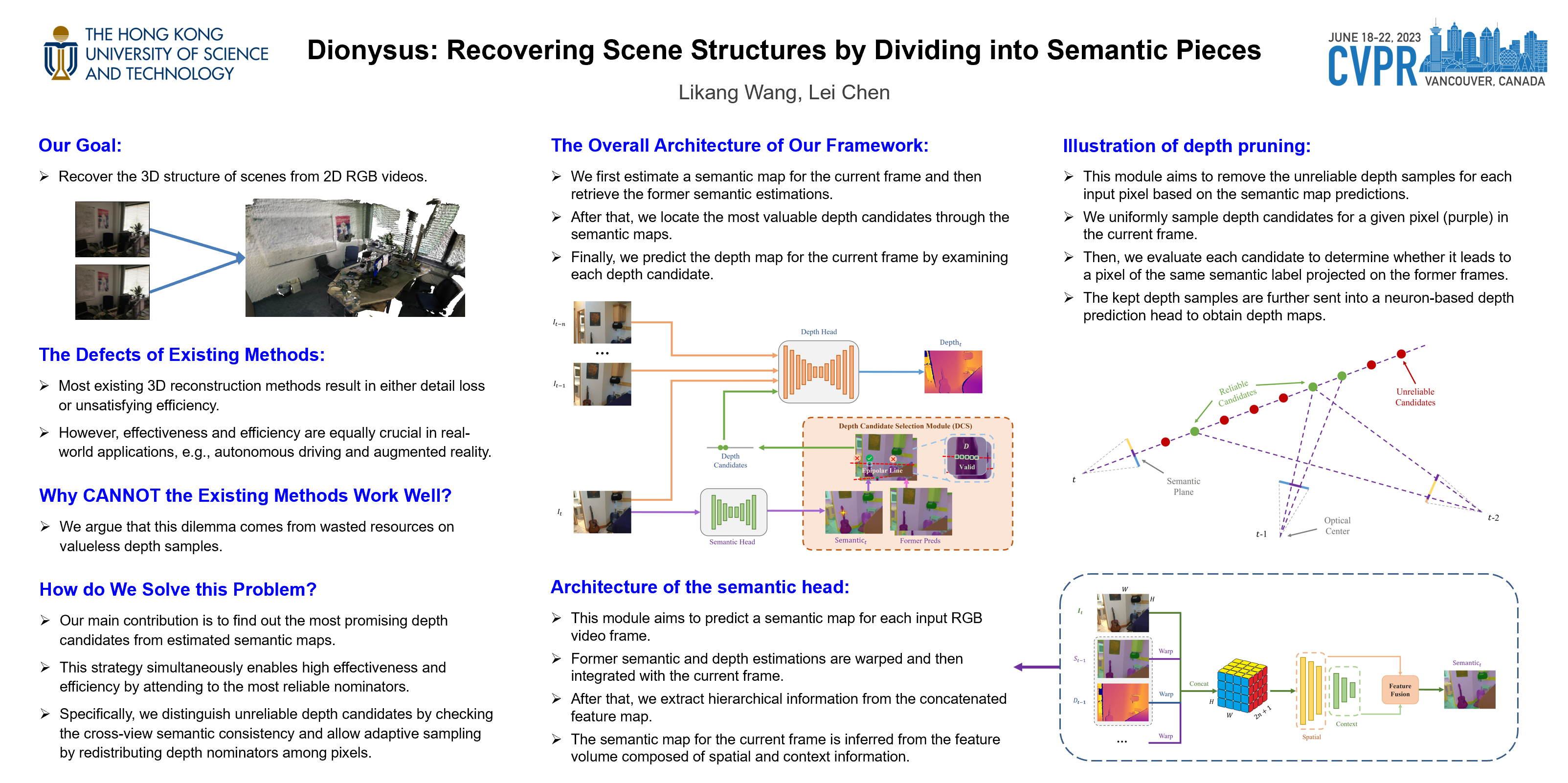
Most existing 3D reconstruction methods result in either detail loss or unsatisfying efficiency. However, effectiveness and efficiency are equally crucial in real-world applications, e.g., autonomous driving and augmented reality. We argue that this dilemma comes from wasted resources on valueless depth samples. This paper tackles the problem by proposing a novel learning-based 3D reconstruction framework named Dionysus. Our main contribution is to find out the most promising depth candidates from estimated semantic maps. This strategy simultaneously enables high effectiveness and efficiency by attending to the most reliable nominators. Specifically, we distinguish unreliable depth candidates by checking the cross-view semantic consistency and allow adaptive sampling by redistributing depth nominators among pixels. Experiments on the most popular datasets confirm our proposed framework’s effectiveness.