BAEFormer: Bi-Directional and Early Interaction Transformers for Bird’s Eye View Semantic Segmentation
{kind=link}
Abstract
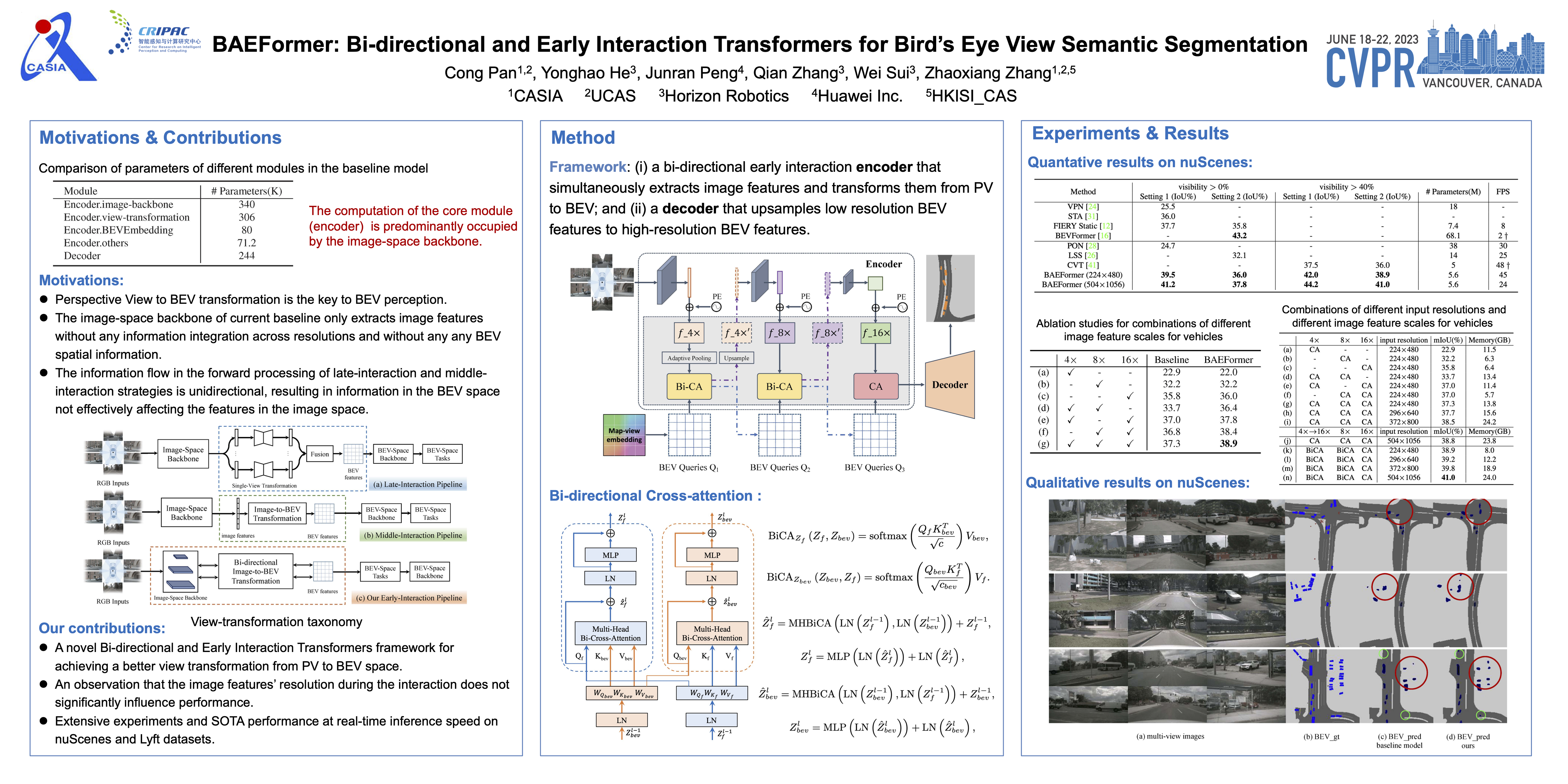
Bird’s Eye View (BEV) semantic segmentation is a critical task in autonomous driving. However, existing Transformer-based methods confront difficulties in transforming Perspective View (PV) to BEV due to their unidirectional and posterior interaction mechanisms. To address this issue, we propose a novel Bi-directional and Early Interaction Transformers framework named BAEFormer, consisting of (i) an early-interaction PV-BEV pipeline and (ii) a bi-directional cross-attention mechanism. Moreover, we find that the image feature maps’ resolution in the cross-attention module has a limited effect on the final performance. Under this critical observation, we propose to enlarge the size of input images and downsample the multi-view image features for cross-interaction, further improving the accuracy while keeping the amount of computation controllable. Our proposed method for BEV semantic segmentation achieves state-of-the-art performance in real-time inference speed on the nuScenes dataset, i.e., 38.9 mIoU at 45 FPS on a single A100 GPU.