MoDAR: Using Motion Forecasting for 3D Object Detection in Point Cloud Sequences
{kind=link}
Abstract
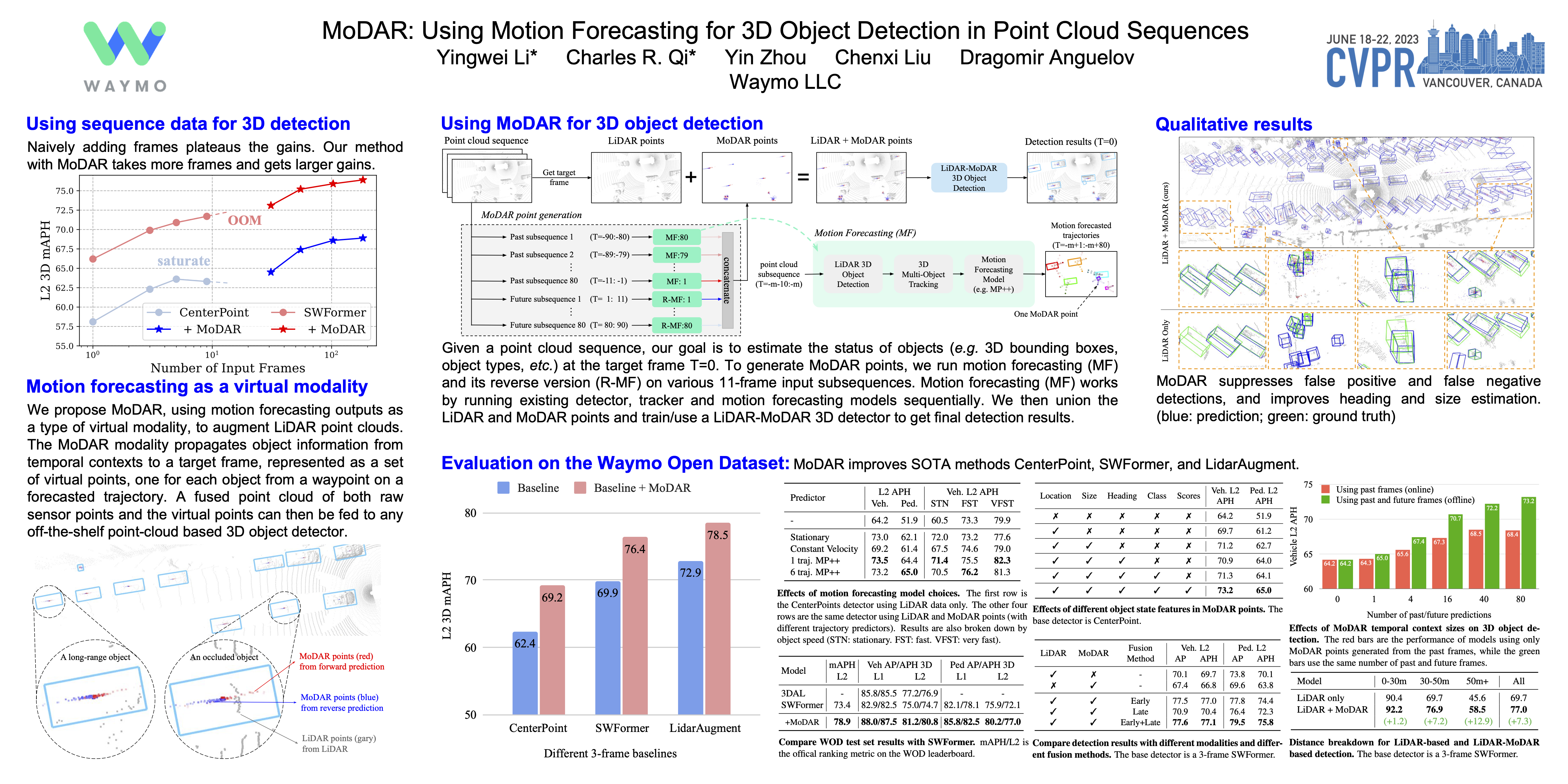
Occluded and long-range objects are ubiquitous and challenging for 3D object detection. Point cloud sequence data provide unique opportunities to improve such cases, as an occluded or distant object can be observed from different viewpoints or gets better visibility over time. However, the efficiency and effectiveness in encoding long-term sequence data can still be improved. In this work, we propose MoDAR, using motion forecasting outputs as a type of virtual modality, to augment LiDAR point clouds. The MoDAR modality propagates object information from temporal contexts to a target frame, represented as a set of virtual points, one for each object from a waypoint on a forecasted trajectory. A fused point cloud of both raw sensor points and the virtual points can then be fed to any off-the-shelf point-cloud based 3D object detector. Evaluated on the Waymo Open Dataset, our method significantly improves prior art detectors by using motion forecasting from extra-long sequences (e.g. 18 seconds), achieving new state of the arts, while not adding much computation overhead.