Learning Visual Representations via Language-Guided Sampling
{kind=link}
Abstract
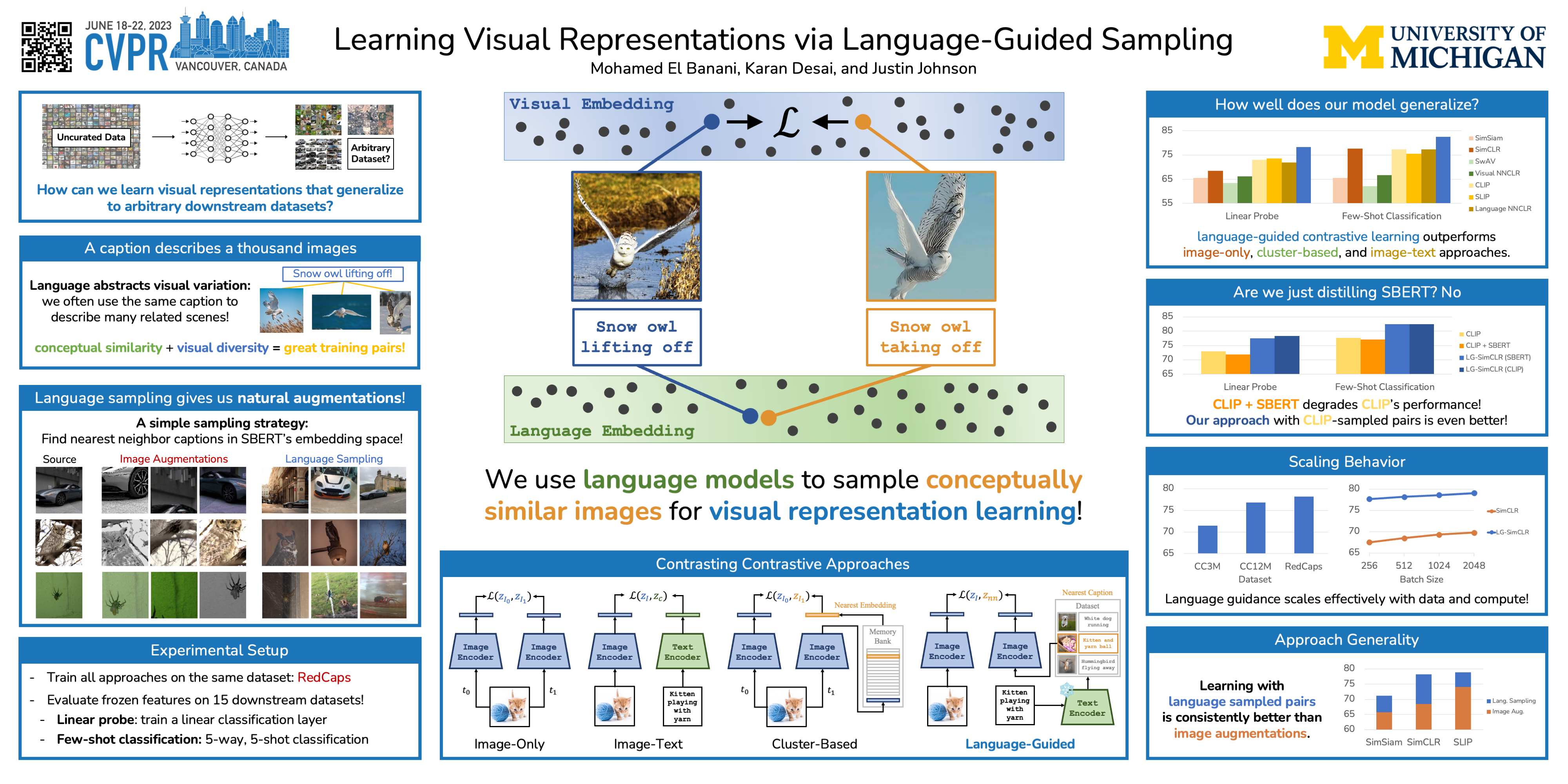
Although an object may appear in numerous contexts, we often describe it in a limited number of ways. Language allows us to abstract away visual variation to represent and communicate concepts. Building on this intuition, we propose an alternative approach to visual representation learning: using language similarity to sample semantically similar image pairs for contrastive learning. Our approach diverges from image-based contrastive learning by sampling view pairs using language similarity instead of hand-crafted augmentations or learned clusters. Our approach also differs from image-text contrastive learning by relying on pre-trained language models to guide the learning rather than directly minimizing a cross-modal loss. Through a series of experiments, we show that language-guided learning yields better features than image-based and image-text representation learning approaches.