3D Spatial Multimodal Knowledge Accumulation for Scene Graph Prediction in Point Cloud
{kind=link}
Abstract
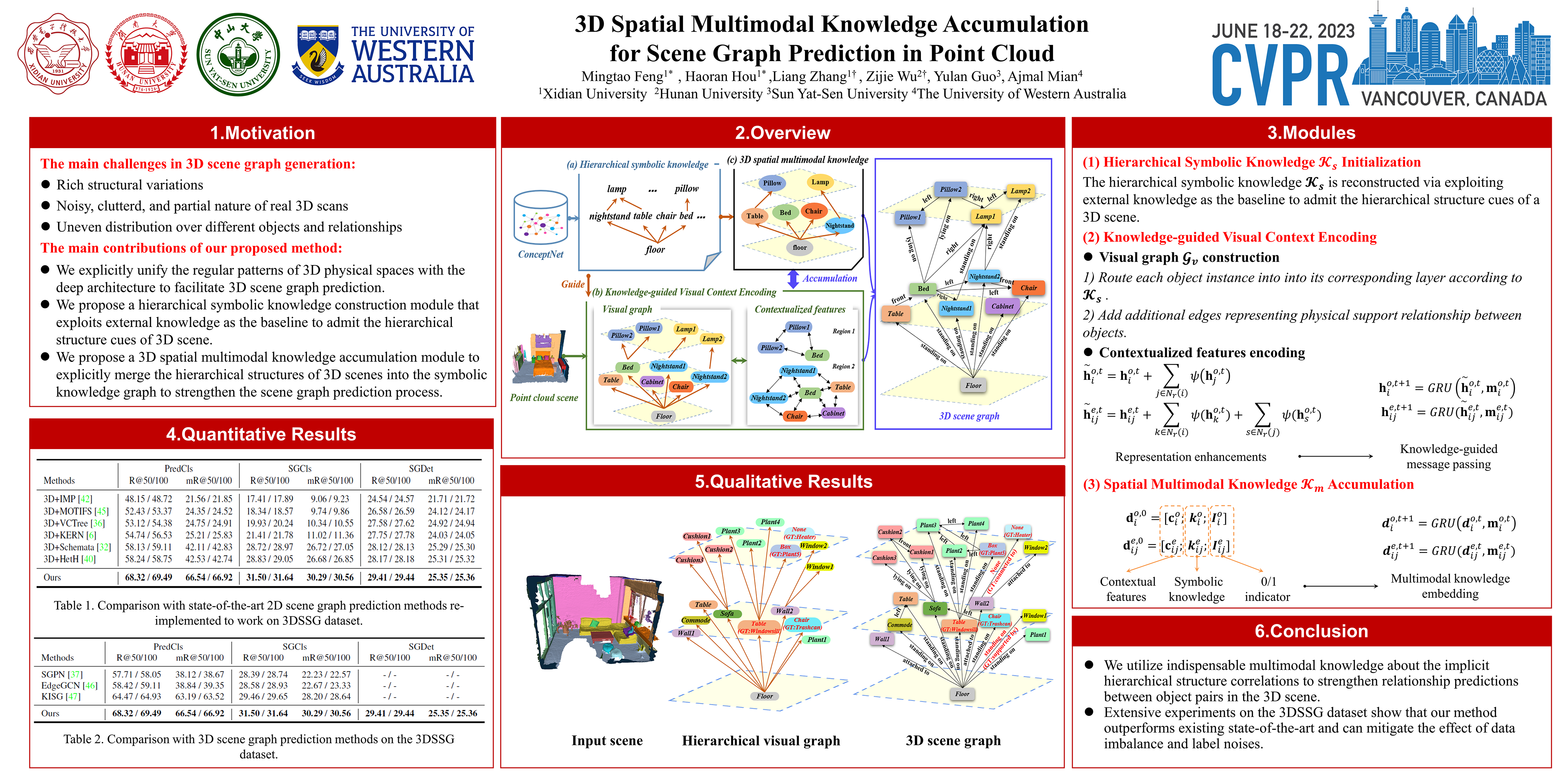
In-depth understanding of a 3D scene not only involves locating/recognizing individual objects, but also requires to infer the relationships and interactions among them. However, since 3D scenes contain partially scanned objects with physical connections, dense placement, changing sizes, and a wide variety of challenging relationships, existing methods perform quite poorly with limited training samples. In this work, we find that the inherently hierarchical structures of physical space in 3D scenes aid in the automatic association of semantic and spatial arrangements, specifying clear patterns and leading to less ambiguous predictions. Thus, they well meet the challenges due to the rich variations within scene categories. To achieve this, we explicitly unify these structural cues of 3D physical spaces into deep neural networks to facilitate scene graph prediction. Specifically, we exploit an external knowledge base as a baseline to accumulate both contextualized visual content and textual facts to form a 3D spatial multimodal knowledge graph. Moreover, we propose a knowledge-enabled scene graph prediction module benefiting from the 3D spatial knowledge to effectively regularize semantic space of relationships. Extensive experiments demonstrate the superiority of the proposed method over current state-of-the-art competitors. Our code is available at https://github.com/HHrEtvP/SMKA.