DETR With Additional Global Aggregation for Cross-Domain Weakly Supervised Object Detection
{kind=link}
Abstract
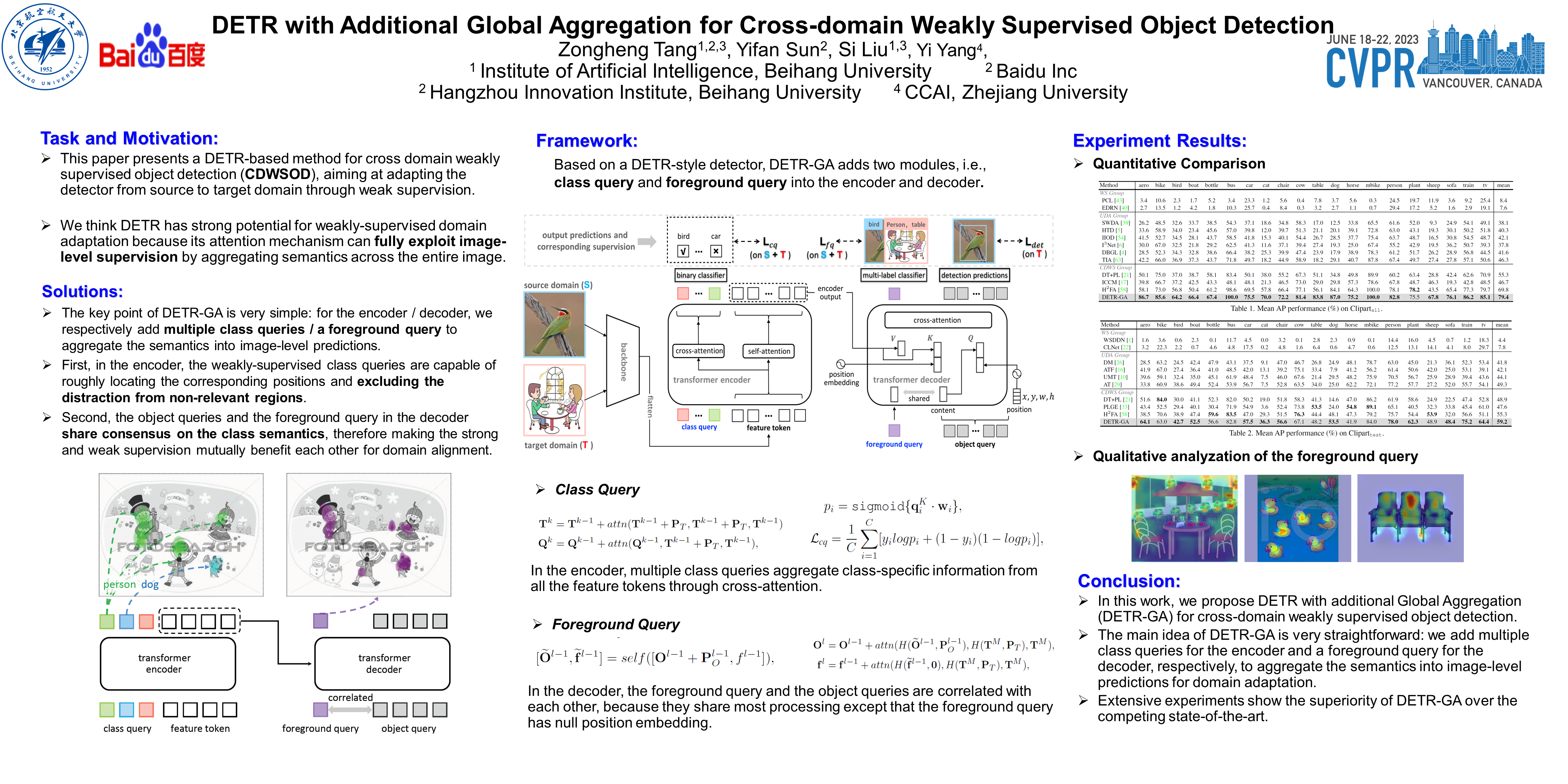
This paper presents a DETR-based method for cross-domain weakly supervised object detection (CDWSOD), aiming at adapting the detector from source to target domain through weak supervision. We think DETR has strong potential for CDWSOD due to an insight: the encoder and the decoder in DETR are both based on the attention mechanism and are thus capable of aggregating semantics across the entire image. The aggregation results, i.e., image-level predictions, can naturally exploit the weak supervision for domain alignment. Such motivated, we propose DETR with additional Global Aggregation (DETR-GA), a CDWSOD detector that simultaneously makes “instance-level + image-level” predictions and utilizes “strong + weak” supervisions. The key point of DETR-GA is very simple: for the encoder / decoder, we respectively add multiple class queries / a foreground query to aggregate the semantics into image-level predictions. Our query-based aggregation has two advantages. First, in the encoder, the weakly-supervised class queries are capable of roughly locating the corresponding positions and excluding the distraction from non-relevant regions. Second, through our design, the object queries and the foreground query in the decoder share consensus on the class semantics, therefore making the strong and weak supervision mutually benefit each other for domain alignment. Extensive experiments on four popular cross-domain benchmarks show that DETR-GA significantly improves CSWSOD and advances the states of the art (e.g., 29.0% --> 79.4% mAP on PASCAL VOC --> Clipart_all dataset).