Practical Network Acceleration With Tiny Sets
{kind=link}
Abstract
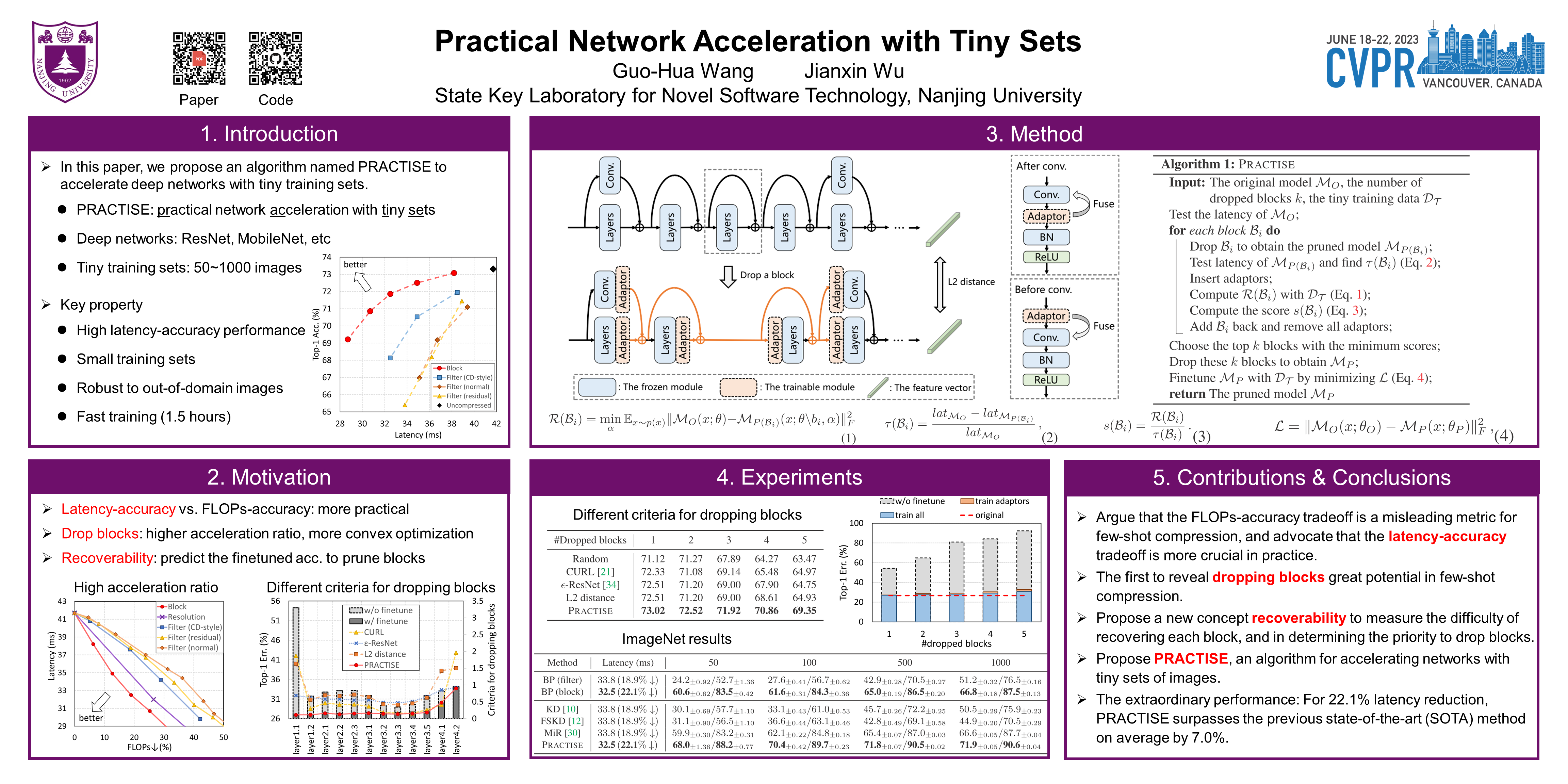
Due to data privacy issues, accelerating networks with tiny training sets has become a critical need in practice. Previous methods mainly adopt filter-level pruning to accelerate networks with scarce training samples. In this paper, we reveal that dropping blocks is a fundamentally superior approach in this scenario. It enjoys a higher acceleration ratio and results in a better latency-accuracy performance under the few-shot setting. To choose which blocks to drop, we propose a new concept namely recoverability to measure the difficulty of recovering the compressed network. Our recoverability is efficient and effective for choosing which blocks to drop. Finally, we propose an algorithm named PRACTISE to accelerate networks using only tiny sets of training images. PRACTISE outperforms previous methods by a significant margin. For 22% latency reduction, PRACTISE surpasses previous methods by on average 7% on ImageNet-1k. It also enjoys high generalization ability, working well under data-free or out-of-domain data settings, too. Our code is at https://github.com/DoctorKey/Practise.