KeyPoint Relative Position Encoding for Face Recognition
{kind=link}
Abstract
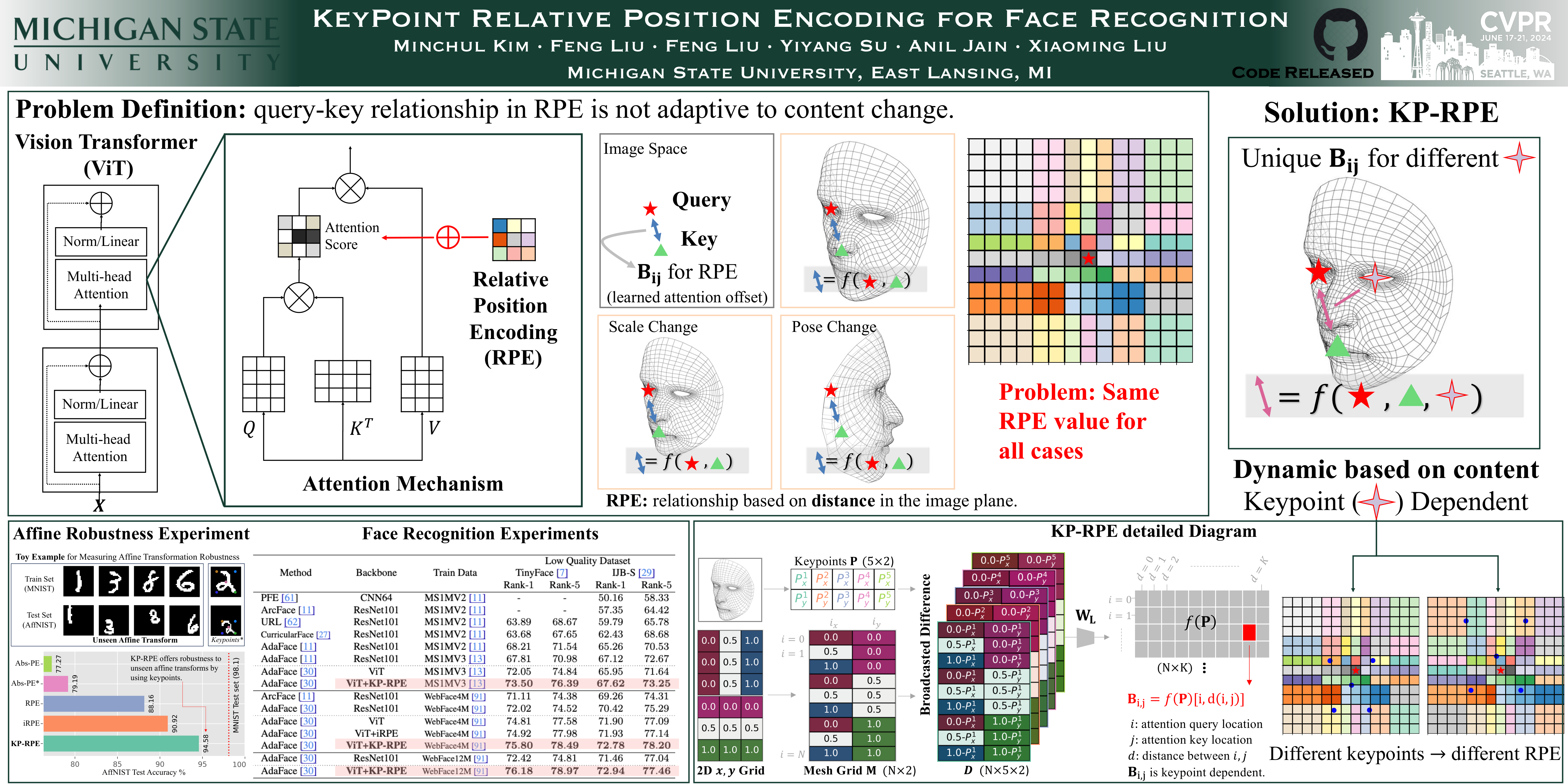
In this paper, we address the challenge of making ViT models more robust to unseen affine transformations. Such robustness becomes useful in various recognition tasks such as face recognition when image alignment failures occur. We propose a novel method called KP-RPE, which leverages key points (e.g.~facial landmarks) to make ViT more resilient to scale, translation, and pose variations. We begin with the observation that Relative Position Encoding (RPE) is a good way to bring affine transform generalization to ViTs. RPE, however, can only inject the model with prior knowledge that nearby pixels are more important than far pixels. Keypoint RPE (KP-RPE) is an extension of this principle, where the significance of pixels is not solely dictated by their proximity but also by their relative positions to specific keypoints within the image. By anchoring the significance of pixels around keypoints, the model can more effectively retain spatial relationships, even when those relationships are disrupted by affine transformations. We show the merit of KP-RPE in face and gait recognition. The experimental results demonstrate the effectiveness in improving face recognition performance from low-quality images, particularly where alignment is prone to failure.Code and pre-trained models will be shared.