Diffusion-ES: Gradient-free Planning with Diffusion for Autonomous and Instruction-guided Driving
{kind=link}
Abstract
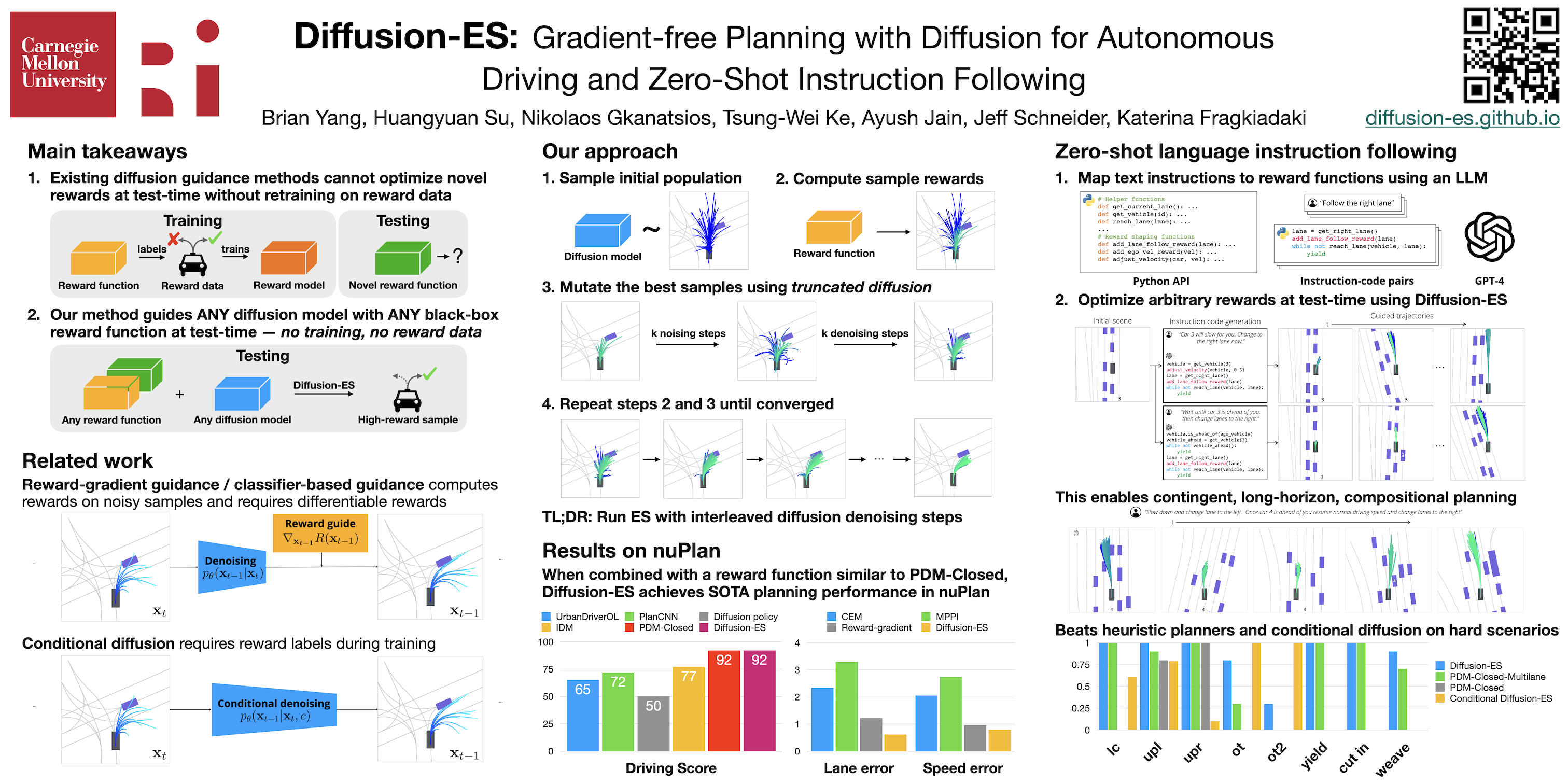
Diffusion models excel at modeling complex and multimodal trajectory distributions for decision-making and control.Reward-gradient guided denoising has been recently proposed to generate trajectories that maximize both a differentiable reward function and the likelihood under the data distribution captured by a diffusion model.Reward-gradient guided denoising requires a differentiable reward function fitted to both clean and noised samples, limiting its applicability as a general trajectory optimizer. In this paper, we propose DiffusionES, a method that combines gradient-free optimization with trajectory denoising to optimize black-box non-differentiable objectives while staying in the data manifold.Diffusion-ES samples trajectories during evolutionary search from a diffusion model and scores them using a black-box reward function. It mutates high-scoring trajectories using a truncated diffusion process that applies a small number of noising and denoising steps, allowing for much more efficient exploration of the solution space.We show that DiffusionES achieves state-of-the-art performance on nuPlan, an established closed-loop planning benchmark for autonomous driving.Diffusion-ES outperforms existing sampling-based planners, reactive deterministic or diffusion-based policies, and reward-gradient guidance.Additionally, we show that unlike prior guidance methods, our method can optimize non-differentiable language-shaped reward functions generated by few-shot LLM prompting.When guided by a human teacher that issues instructions to follow, our method can generate novel, highly complex behaviors, such as aggressive lane weaving, which are not present in the training data.This allows us to solve the hardest nuPlan scenarios which are beyond the capabilities of existing trajectory optimization methods and driving policies.