VicTR: Video-conditioned Text Representations for Activity Recognition
Kumara Kahatapitiya ⋅ Anurag Arnab ⋅ Arsha Nagrani ⋅ Michael Ryoo
2024 Poster
{kind=link}
Abstract
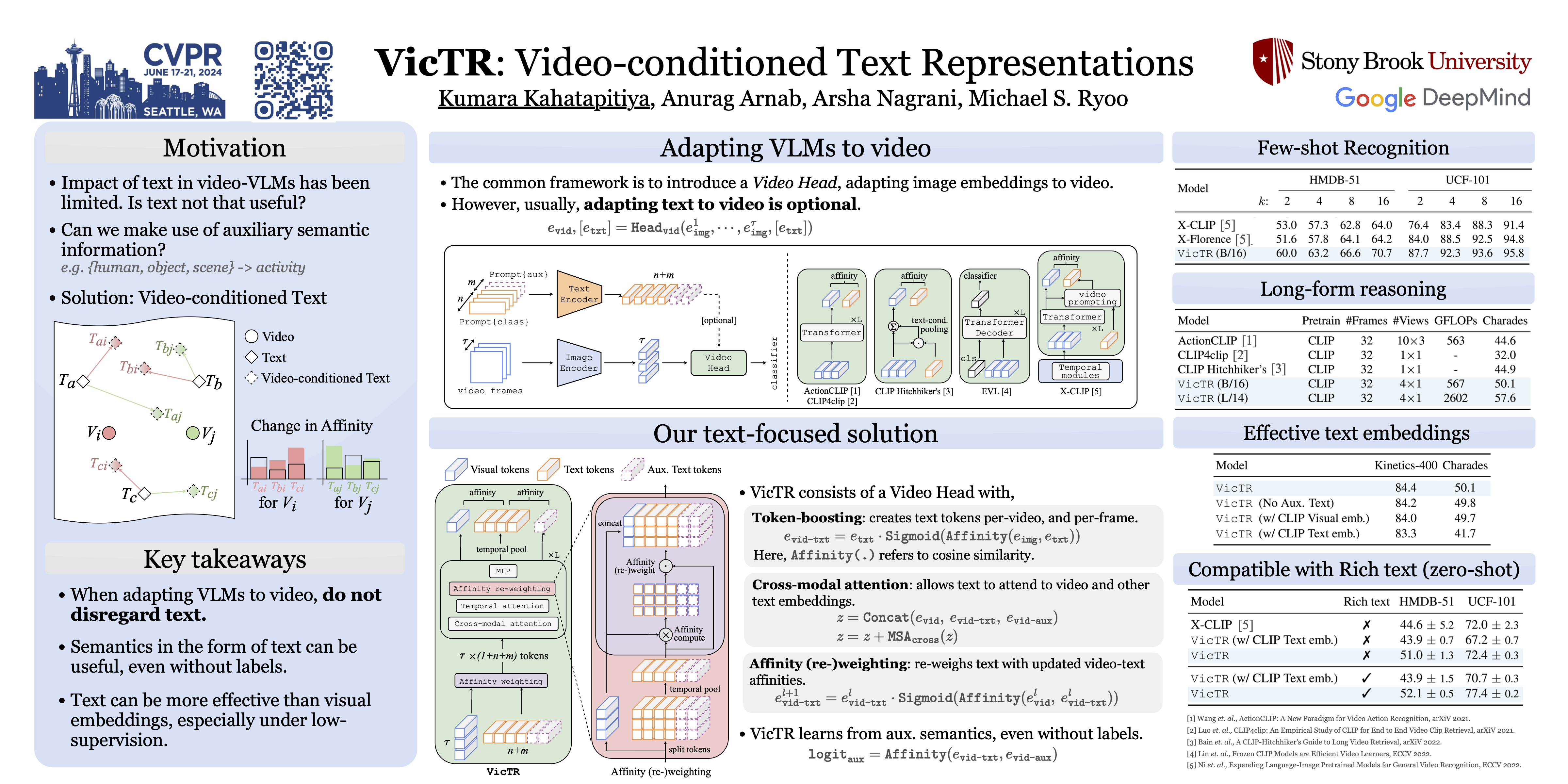
Vision-Language models (VLMs) have excelled in the image-domain--- especially in zero-shot settings--- thanks to the availability of vast pretraining data (i.e., paired image-text samples). However for videos, such paired data is not as abundant. Therefore, video-VLMs are usually designed by adapting pretrained image-VLMs to the video-domain, instead of training from scratch. All such recipes rely on augmenting visual embeddings with temporal information (i.e., image $\rightarrow$ video), often keeping text embeddings unchanged or even being discarded. In this paper, we argue the contrary, that better video-VLMs can be designed by focusing more on augmenting text, rather than visual information. More specifically, we introduce Video-conditioned Text Representations (VicTR): a form of text embeddings optimized w.r.t. visual embeddings, creating a more-flexible contrastive latent space. Our model can further make use of freely-available semantic information, in the form of visually-grounded auxiliary text (e.g. object or scene information). We evaluate our model on few-shot, zero-shot (HMDB-51, UCF-101), short-form (Kinetics-400) and long-form (Charades) activity recognition benchmarks, showing strong performance among video-VLMs.
Chat is not available.
Successful Page Load