T4P: Test-Time Training of Trajectory Prediction via Masked Autoencoder and Actor-specific Token Memory
{kind=link}
Abstract
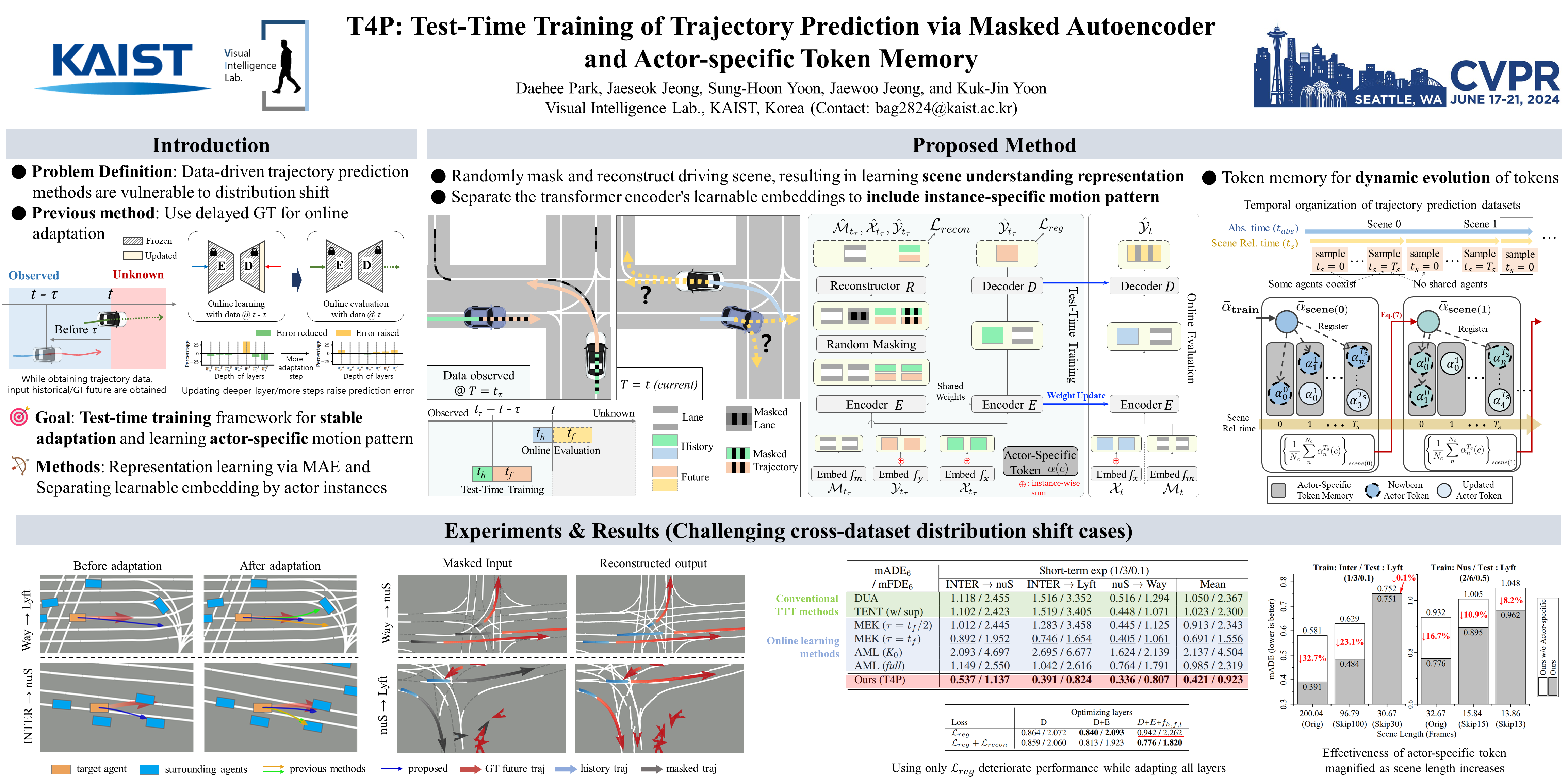
Trajectory prediction is a challenging problem that requires considering interactions among multiple actors and the surrounding environment.While data-driven approaches have been used to address this complex problem, they suffer from unreliable predictions under distribution shift during test time.Accordingly, several online learning methods have been proposed using regression loss from the ground truth of observed data leveraging the auto-labeling nature of trajectory prediction task.We tackle two issues of the previous methods.First, we tackle that online adaptation is done with a few GT samples in a delayed time stamp.It makes underfitting or overfitting, so previous works only optimized the last layers of motion decoder.We employ the masked autoencoder (MAE) for representation learning to encourage complex interaction modeling in shifted test distribution for updating deeper layers.Second, we emphasize that driving data comes sequentially during test time, unlike random shuffles during training time.Therefore, we can access a specific past motion pattern for each actor instance.To address this, we propose an actor-specific token memory, enabling the learning of personalized motion pattern during test-time training.Our proposed method has been validated across various challenging cross-dataset distribution shift scenarios including nuScenes, Lyft, Waymo, and Interaction. Our method surpasses the performance of existing state-of-the-art online learning methods in terms of both prediction accuracy and computational efficiency.