Imagine Before Go: Self-Supervised Generative Map for Object Goal Navigation
{kind=link}
Abstract
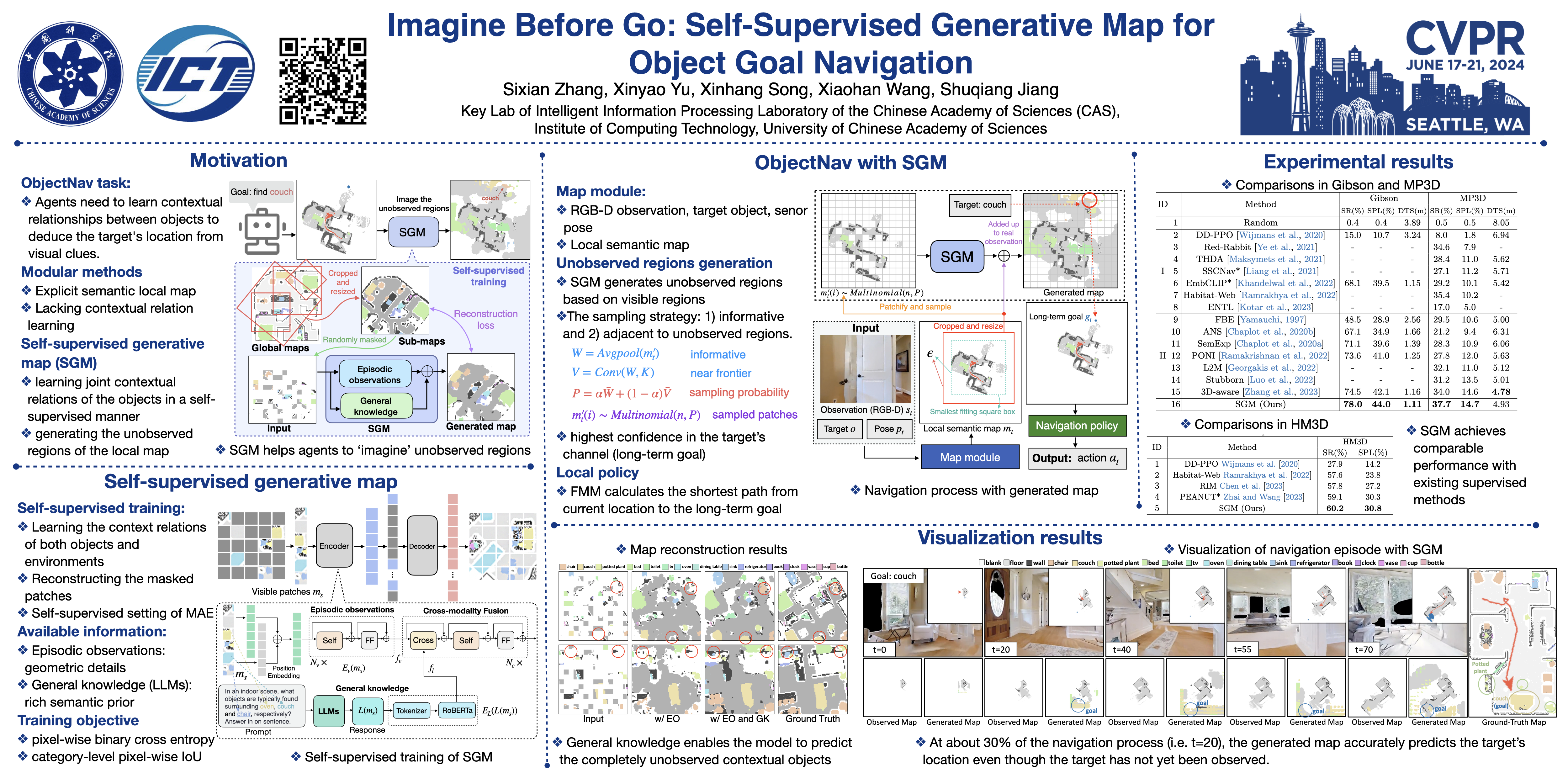
The Object Goal navigation (ObjectNav) task requires the agent to navigate to a specified target in an unseen environment. Since the environment layout is unknown, the agent needs to infer the unknown contextual objects from partially observations, thereby deducing the likely location of the target. Previous end-to-end RL methods learn the contextual relation with implicit representations while they lack notion of geometry. Alternatively, modular methods construct a local map for recording the observed geometric structure of unseen environment, however, lacking the reasoning of contextual relation limits the exploration efficiency. In this work, we propose the self-supervised generative map (SGM), a modular method that learns the explicit context relation via self-supervised learning. The SGM is trained to leverage both episodic observations and general knowledge to reconstruct the masked pixels of a cropped global map. During navigation, the agent maintains an incomplete local semantic map, meanwhile, the unknown regions of the local map are generated by the pre-trained SGM. Based on the scaled-up local map, the agent sets the predicted location of the target as the goal and moves towards it. Experiments on Gibson, MP3D and HM3D demonstrate the effectiveness and efficiency of our method.