Open Vocabulary Semantic Scene Sketch Understanding
{kind=link}
Abstract
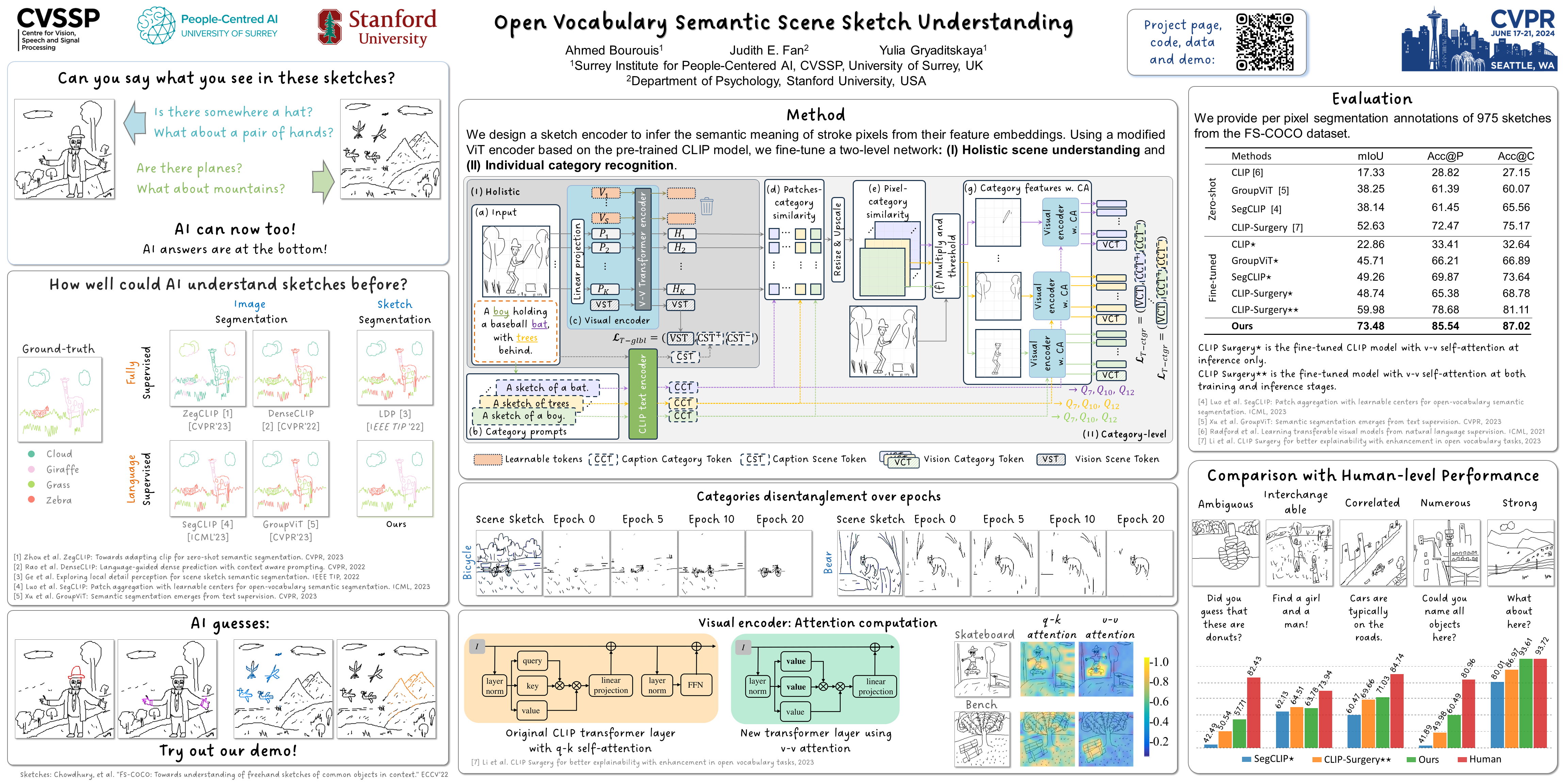
We study the underexplored but fundamental vision problem of machine understanding of abstract freehand scene sketches. We introduce a sketch encoder that results in semantically-aware feature space, which we evaluate by testing its performance on a semantic sketch segmentation task. To train our model we rely only on the availability of bitmap sketches with their brief captions and do not require any pixel-level annotations. To obtain generalization to a large set of sketches and categories, we build on a vision transformer encoder pretrained with the CLIP model. We freeze the text encoder and perform visual-prompt tuning of the visual encoder branch while introducing a set of critical modifications. Firstly, we augment the classical key-query (k-q) self-attention blocks with value-value (v-v) self-attention blocks. Central to our model is a two-level hierarchical network design that enables efficient semantic disentanglement: The first level ensures holistic scene sketch encoding, and the second level focuses on individual categories. We, then, in the second level of the hierarchy, introduce a cross-attention between textual and visual branches. Our method outperforms zero-shot CLIP pixel accuracy of segmentation results by 37 points, reaching an accuracy of 85.5\% on the FS-COCO sketch dataset. Finally, we conduct a user study that allows us to identify further improvements needed over our method to reconcile machine and human understanding of scene sketches.