Distilled Datamodel with Reverse Gradient Matching
{kind=link}
Abstract
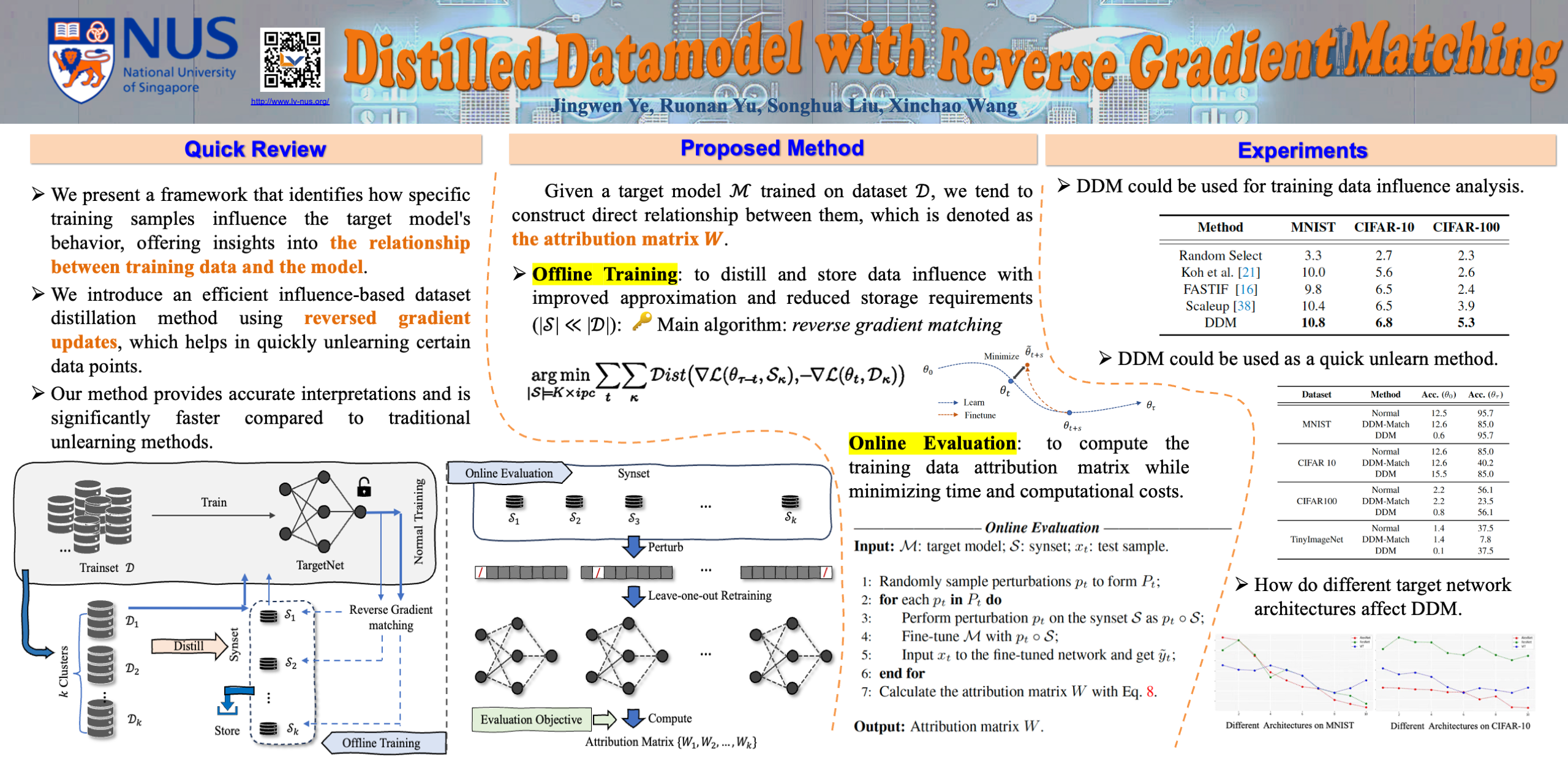
The proliferation of large-scale AI models trained on extensive datasets has revolutionized machine learning. With these models taking on increasingly central roles in various applications, the need to understand their behavior and enhance interpretability has become paramount.To investigate the impact of changes in training data on a pre-trained model, a common approach is leave-one-out retraining. This entails systematically altering the training dataset by removing specific samples to observe resulting changes within the model. However, retraining the model for each altered dataset presents a significant computational challenge, given the need to perform this operation for every dataset variation.In this paper, we introduce an efficient framework for assessing data impact, comprising offline training and online evaluation stages. During the offline training phase, we approximate the influence of training data on the target model through a distilled synset, formulated as a reversed gradient matching problem. For online evaluation, we expedite the leave-one-out process using the synset, which is then utilized to compute the attribution matrix based on the evaluation objective.Experimental evaluations, including training data attribution and assessments of data quality, demonstrate that our proposed method achieves comparable model behavior evaluation while significantly speeding up the process compared to the direct retraining method.