From Variance to Veracity: Unbundling and Mitigating Gradient Variance in Differentiable Bundle Adjustment Layers
{kind=link}
Abstract
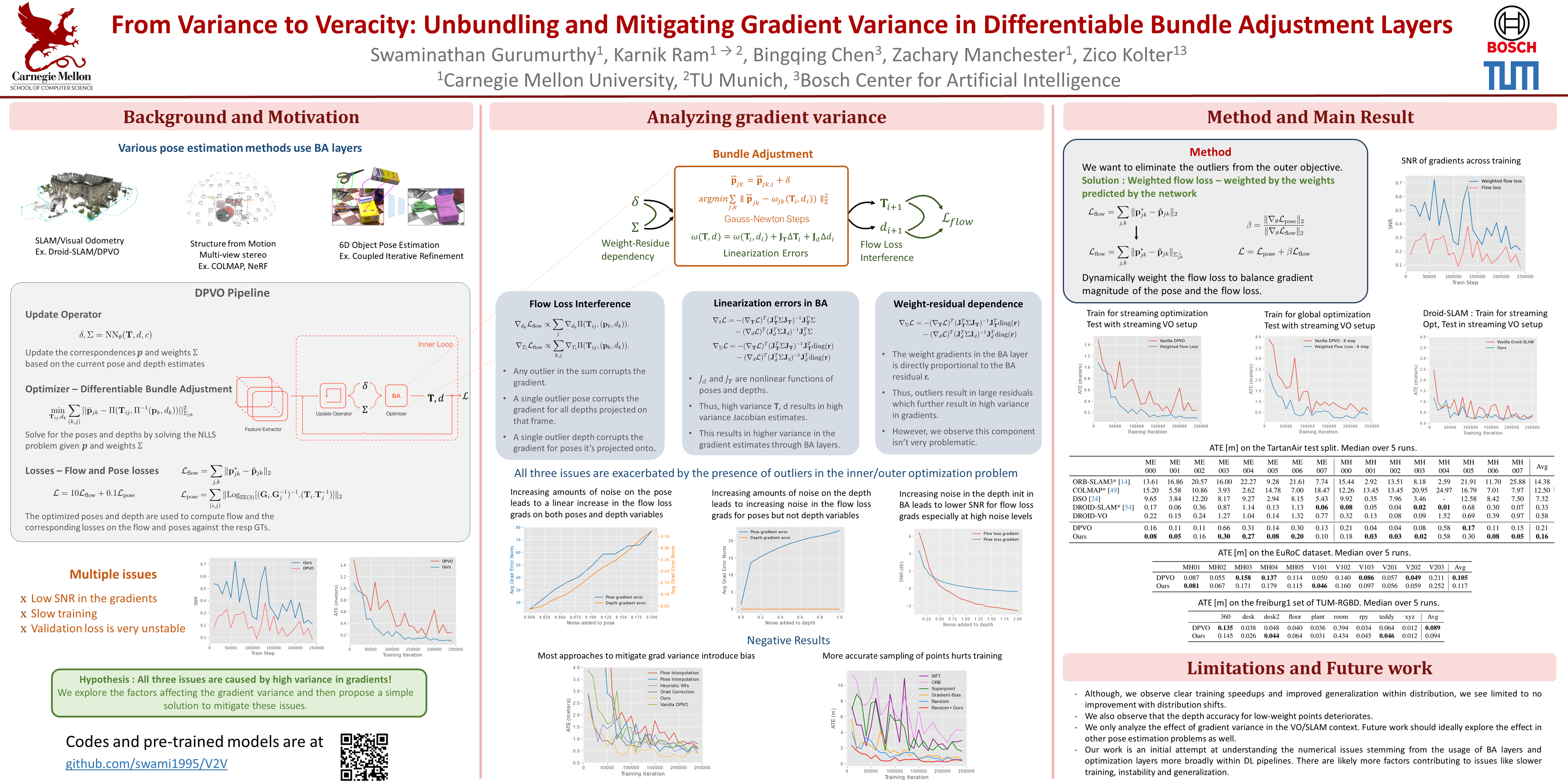
Various pose estimation and tracking problems in robotics can be decomposed into a correspondence estimation problem (often computed using a deep network) followed by a weighted least squares optimization problem to solve for the poses. Recent work has shown that coupling the two problems by iteratively refining one conditioned on the other's output yields SOTA results across domains. However, training these models has proved challenging, requiring a litany of tricks to stabilize and speed up training. In this work, we take the visual odometry problem as an example and identify three plausible causes: (1) flow loss interference, (2) linearization errors in the bundle adjustment (BA) layer, and (3) dependence of weight gradients on the BA residual. We show how these issues result in noisy and higher variance gradients, potentially leading to a slow down in training and instabilities. We then propose a simple solution to reduce the gradient variance by using the weights predicted by the network in the inner optimization loop to also weight the correspondence objective in the training problem. This helps the training objective 'focus' on the more important points, thereby reducing the variance and mitigating the influence of outliers. We show that the resulting method leads to faster training and can be more flexibly trained in varying training setups without sacrificing performance. In particular we show 2-2.5x training speedups over a baseline visual odometry model we modify.