Infer from What You Have Seen Before: Temporally-dependent Classifier for Semi-supervised Video Segmentation
{kind=link}
Abstract
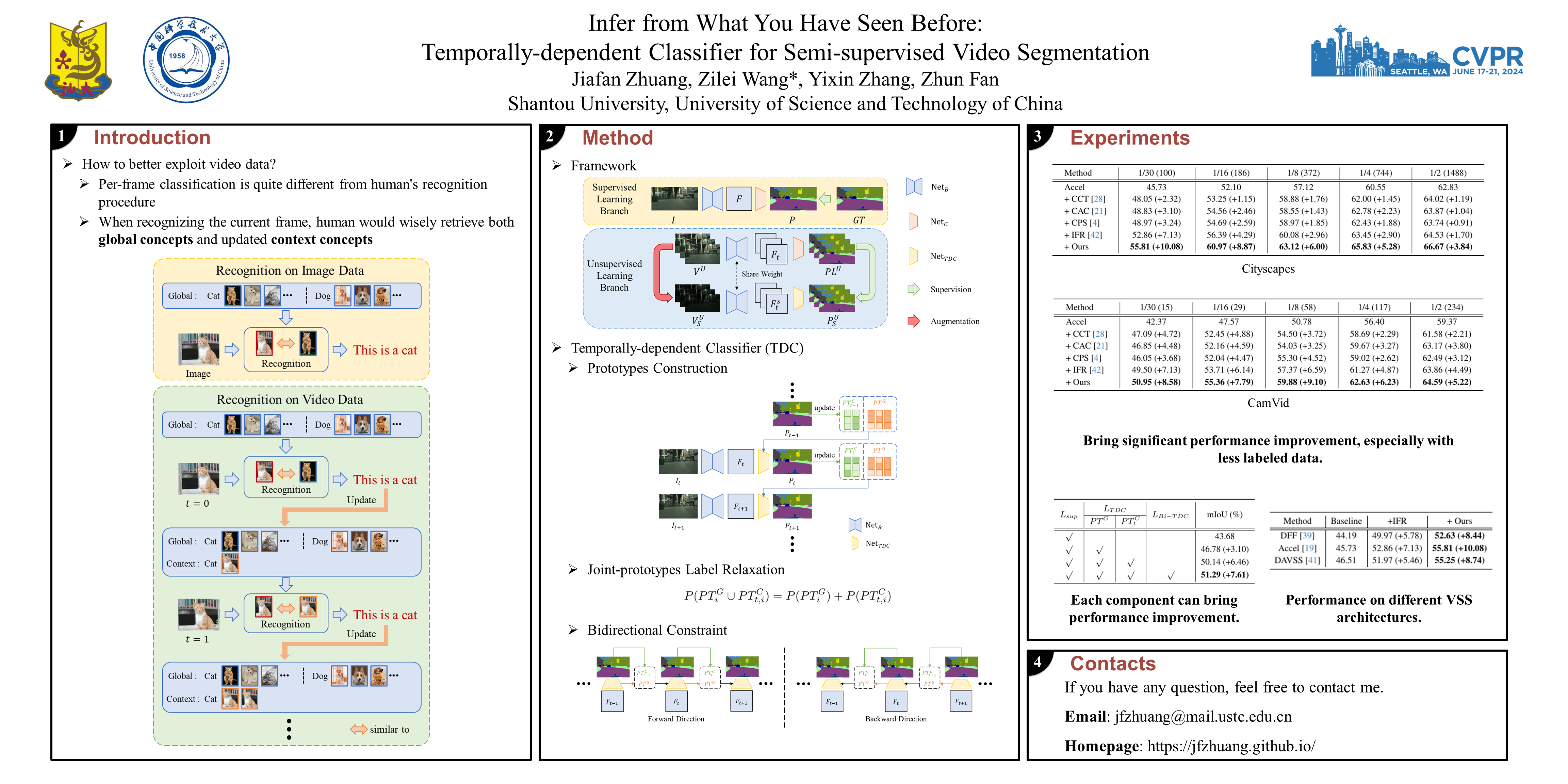
Due to high expense of human labor, one major challenge for semantic segmentation in real-world scenarios is the lack of sufficient pixel-level labels, which is more serious when processing video data. To exploit unlabeled data for model training, semi-supervised learning methods attempt to construct pseudo labels or various auxiliary constraints as supervision signals. However, most of them just process video data as a set of independent images in a per-frame manner. The rich temporal relationships are ignored, which can serve as valuable clues for representation learning. Besides, this per-frame recognition paradigm is quite different from that of humans. Actually, benefited from the internal temporal relevance of video data, human would wisely use the distinguished semantic concepts in historical frames to aid the recognition of the current frame. Motivated by this observation, we propose a novel temporally-dependent classifier (TDC) to mimic the human-like recognition procedure. Comparing to the conventional classifier, TDC can guide the model to learn a group of temporally-consistent semantic concepts across frames, which essentially provides an implicit and effective constraint. We conduct extensive experiments on Cityscapes and CamVid, and the results demonstrate the superiority of our proposed method to previous state-of-the-art methods.