TeMO: Towards Text-Driven 3D Stylization for Multi-Object Meshes
{kind=link}
Abstract
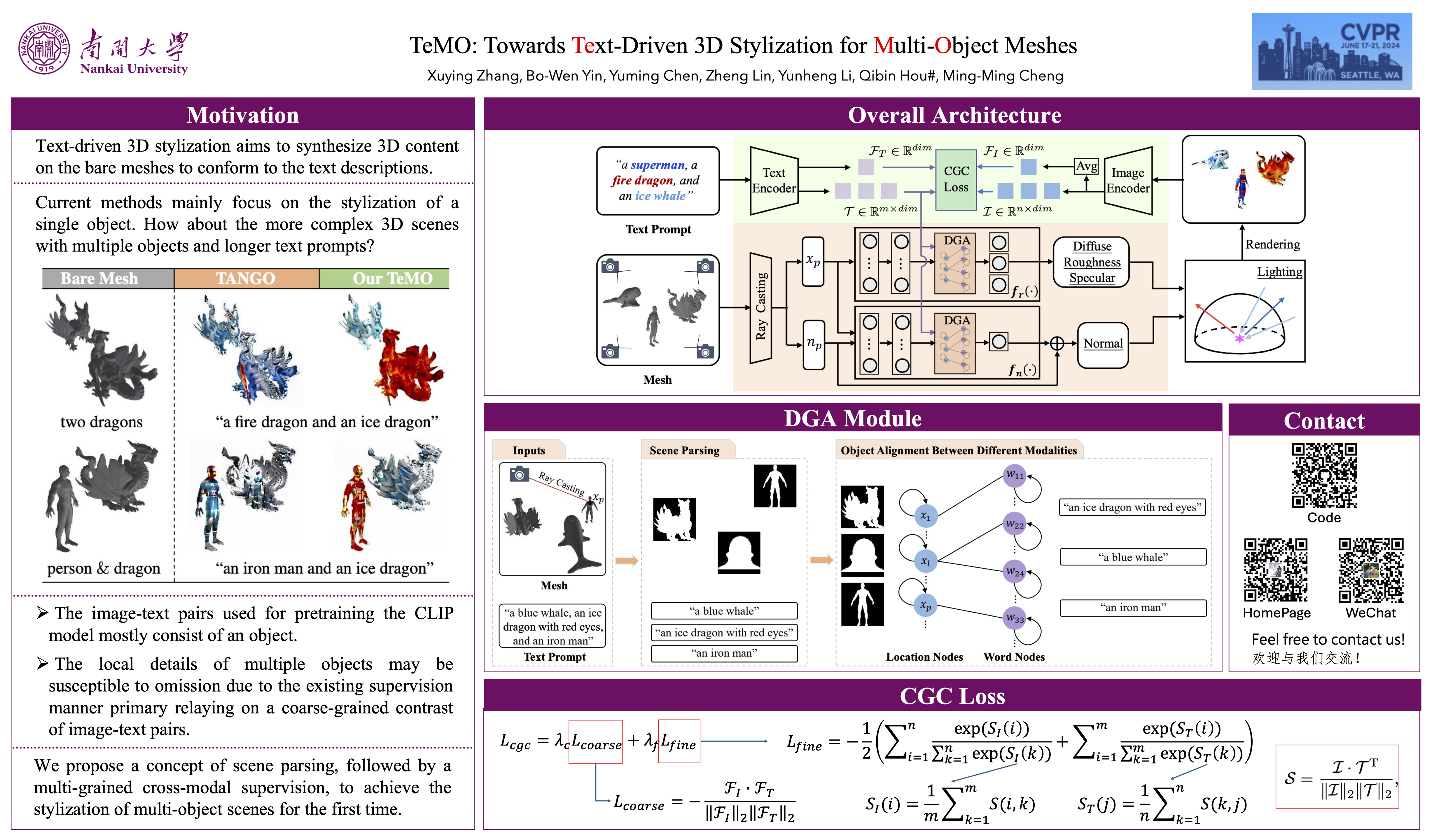
Recent progress in text-driven 3D object stylization has been considerably promoted by the Contrastive Language-Image Pre-training (CLIP) model. However, the stylization of multi-object 3D scenes is impeded in that the image-text pairs used for pre-training CLIP mostly consist of an object. Meanwhile, the local details of multiple objects may be susceptible to omission due to the existing supervision manner primarily relying on coarse-grained contrast of image-text pairs. To overcome these challenges, we present a novel framework, dubbed TeMo, to parse multi-object 3D scenes and edit their styles under the contrast supervision at multiple levels. We first propose a Graph-based Cross Attention (GCA) module to distinguishably reinforce the features of 3D surface points. Particularly, a cross-modal graph is constructed to align the object points accurately and noun phrases decoupled from the 3D mesh and textual description. Then, we develop a Cross-Grained Contrast (CGC) supervision system, where a fine-grained loss between the words in the textual description and the randomly rendered images are constructed to complement the coarse-grained loss. Extensive experiments show that our method can synthesize desired styles and outperform the existing methods over a wide range of multi-object 3D meshes. Our codes and results will be made publicly available.