Omni-SMoLA: Boosting Generalist Multimodal Models with Soft Mixture of Low-rank Experts
 Highlight
Highlight
{kind=link}
Abstract
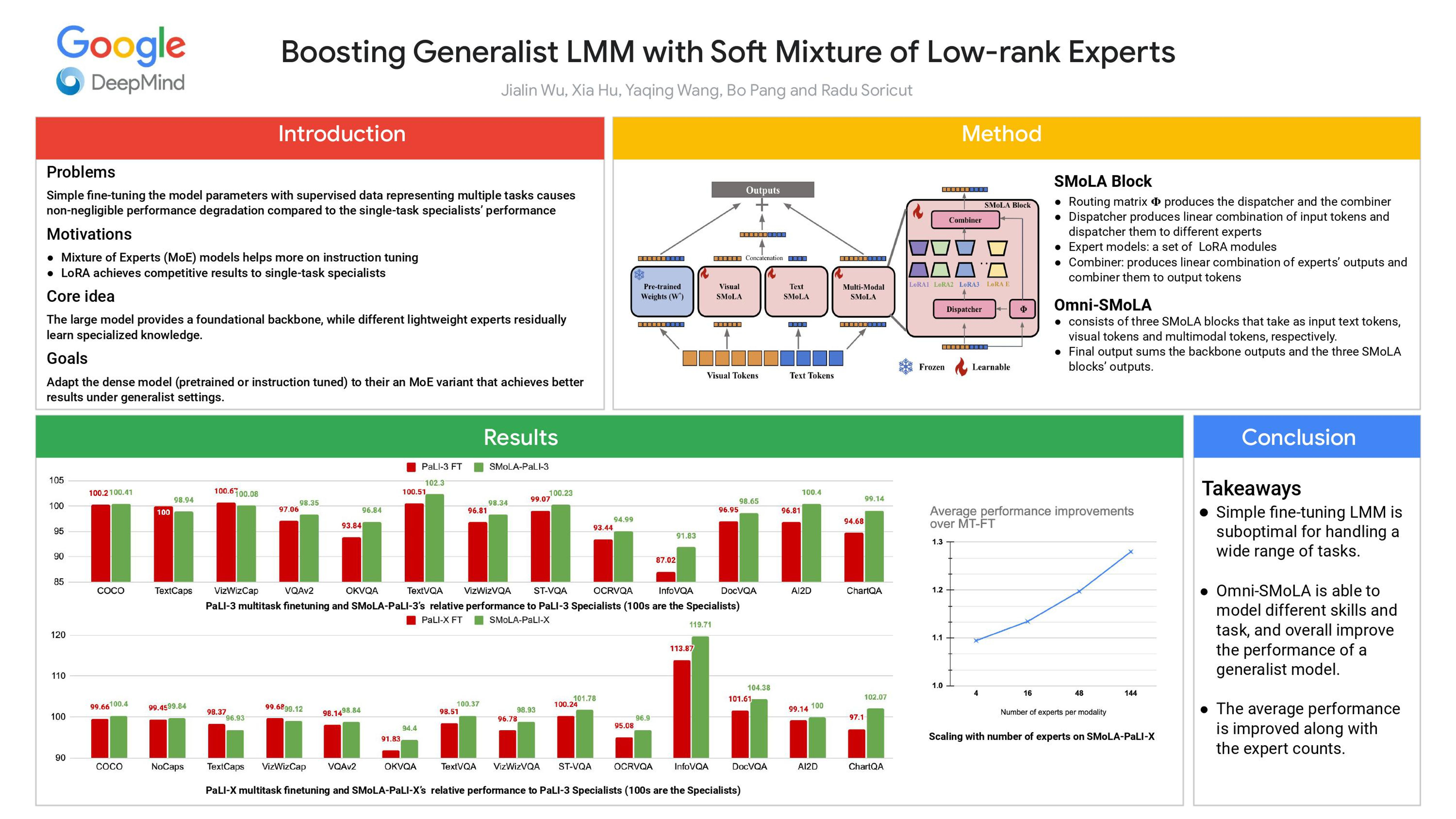
Large multi-modal models (LMMs) exhibit remarkable performance across numerous tasks. However, generalist LMMs often suffer from performance degradation when tuned over a large collection of tasks. Recent research suggests that Mixture of Experts (MoE) architectures are useful for instruction tuning, but for LMMs of parameter size around O(50-100B), the prohibitive cost of replicating and storing the expert models severely limits the number of experts we can use.We propose Omni-SMoLA, an architecture that uses the Soft MoE approach to (softly) mix many multimodal low rank experts, and avoids introducing a significant number of new parameters compared to conventional MoE models. The core intuition here is that the large model provides a foundational backbone, while different lightweight experts residually learn specialized knowledge, either per-modality or multimodally. Extensive experiments demonstrate that the SMoLA approach helps improve the generalist performance across a broad range of generative vision-and-language tasks, achieving new SoTA generalist performance that often matches or outperforms single specialized LMM baselines, as well as new SoTA specialist performance.